北航面向对象与程序设计课程作业,表达式展开Expr-expansion 3.0,对2.1的迭代开发。
插曲:对2.0的代码风格进行美化及debug。形成Expr-expansion 2.1。
新增需求:自定义函数嵌套,求导。
这一次的博客主要是向大家展示架构,就不做过多的细节论述了,相信大家经过前几次的迭代,已经具备了一定的结构抽象的能力,不必局限于具体的细节呈现了。
hw3_log
对hw_2的教训的整理以及策略的变化(2.1)
- 使用泛型写静态方法对于ArrayList容器进行不考虑顺序判等(我把这个作为静态方法放置在MainClass中。
- 当然已经有不少同学在第三次的作业中开始使用HashMap高效率的索引合并,这种方法值得借鉴。
1 | public static <T> boolean isCollectionMatch(Collection<T> list1, Collection<T> list2) { |
- hw2的失败来自于在poly部分的计算复杂化以及toPoly.toString()的复用(大家一定要保持良好的代码风格呀!!!
- 每一次的toPoly都是一次巨大的开销,我还去反复调用((
- 因为toString的方法里也会调用toPoly,所以我们也需要去除toString的重复调用
- 我为了优化打了许多的特判,然后代码风格上出现了问题(我在每一个判断的if条件语句中重复调用了toPoly或者toString的方法,导致性能开销极大。
- 所以我去掉了条件里的重复调用,只用了一个toPoly(),如下:
1 | //before optimize |
我的Poly包与Expr包之间要有一个比较明显的界限分离,即在Poly类中不应该再调用类的toPoly的方法,也不应该含有Expr包的属性。在Expr中,也只在最后才使用到toPoly的方法。
- 类与类之间的数据太共享不是一个好事!!!
- 所以我把三角函数的单独元TriItem中存入一个 factorPoly=factor.toPoly() 作为属性,而不是以factor作为属性(这其实也解决了我的上一个问题。
然后就是对于Poly类中的二元运算,因为需要避免改变传入值的值,所以我每一次运算都会进行一次深克隆
- 所有的二元运算的静态方法都变成了改变this的一元运算,防止每一次都深克隆带来巨大的开销。(只需要保证方法不改变传入值即可
ExprExpansion2.1是一次在代码风格上的巨大升级,优化后的代码行数直接由2.0的1300多行来到了1100多行
- 而且在优化以后,方法的复杂度大大降低,详细见下图(只给出复杂度超标的方法):
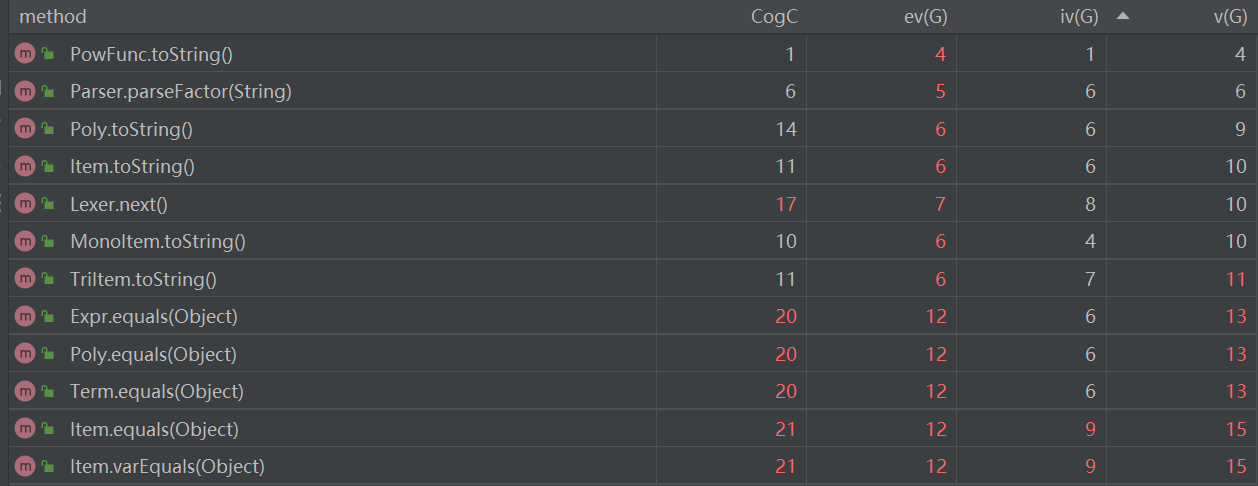
- 优化后:
- EE2.0(ExprExpansion2.0)的时候那些用到了ArrayList判等的Equals方法全都暴雷,原因就是重复造了很多轮子。
- 其余的复杂度也有所下降。
hw3新增需求
- 自定义函数定义中可以包含自定义函数(保证不会递归调用)和求导算子(先求导后代入)(既任意因子)
- 表达式增加求导算子(最多只能出现一次,也就是不会有高阶导)
形式化表述
- 详细的形式化表述就不给出了,变化就是因子增加了求导因子,然后自定义函数中可以调用自定义函数
下面是省流版:
Expr -> [±] Term | Expr ‘±’ Term
- Term -> [±] Factor | Term ‘*‘ Factor
- Factor -> Variable | ConNum | ExprFactor | Deriv
- Variable-> PowFunc | TriFunc | DefFunc
- PowFunc -> indepVar index
- ConNum -> [±] Num
- ExpFac -> ‘(‘ Expr ‘)’ index
- TriFunc -> ‘sin’ ‘(‘ Factor ‘)’ index | ‘cos’ ‘(‘ Factor ‘)’ index
- DefFunc -> (‘f’|’g’|’h’) ‘(‘ Factor[\times 3] ‘)’
- (‘f’|’g’|’h’) ‘(‘ indepVar[\times 3] ‘)’ = Expr
Deriv -> operator ‘(‘ Expr ‘)’
- operator -> d indepVar
Num -> ( 0 ~ 9 ) { 0 ~ 9 }
- indepVar-> (‘x’ | ‘y’ | ‘z’)
- index -> [‘**‘ [‘+’] Num]
需求分析
具体实现
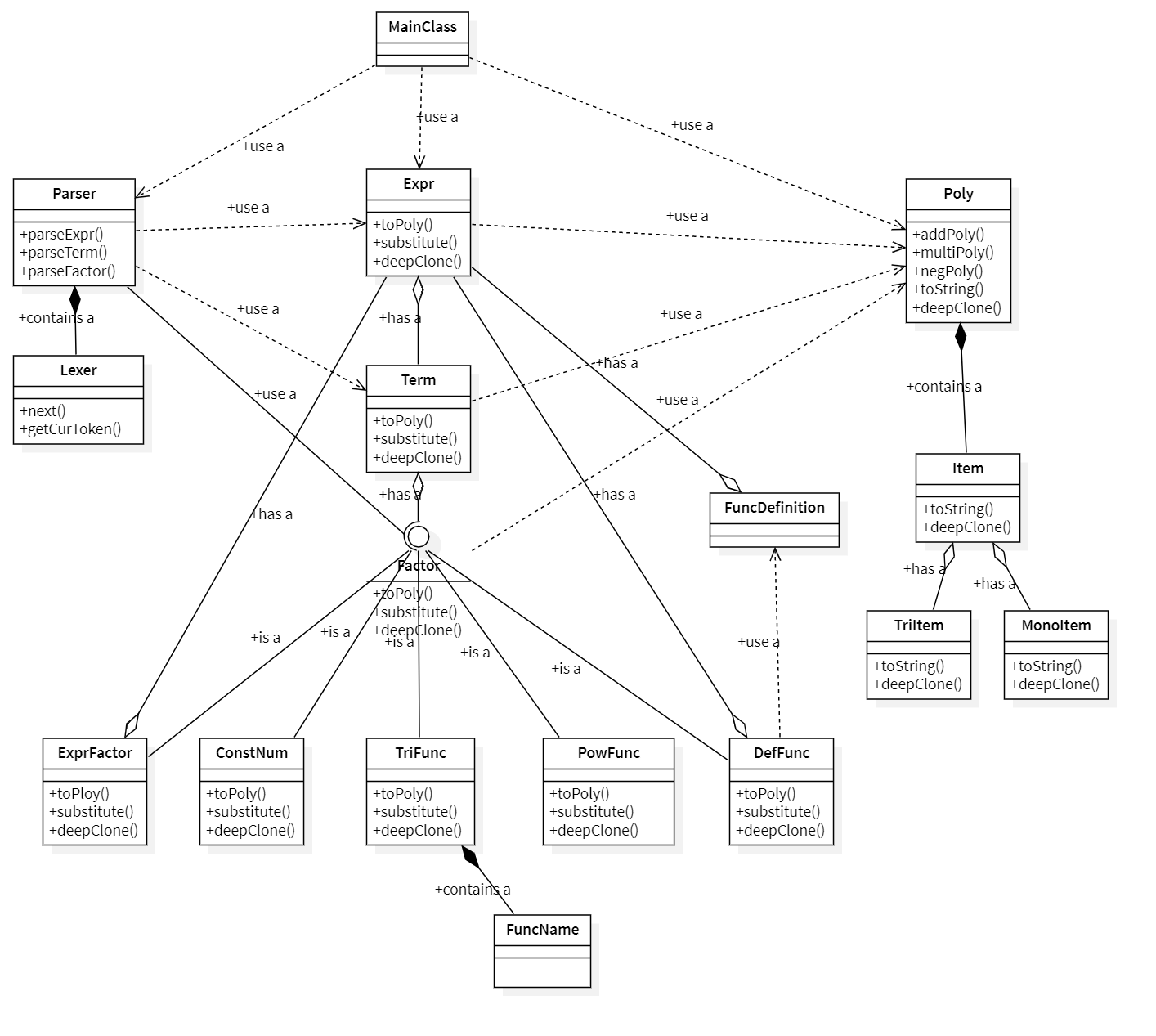
uml类图以及简述

- 第三次的迭代跨度不是很大,架构比较完整合适的话基本上半天能够码完
- 但是毕竟三次迭代过去了,我把完整类图放出来应该问题也不大的,但是我发现可能有点乱了,所以加了一些颜色做了横向层次上的区分(图可以放大看。
- 除了纵向的递归的层次之外,从类图中我们可以明显的看出,分为解析类,表达式类,化简多项式类。
- 三者之间结构的关系相信1.0和2.0的博客已经说的很清楚了,这里就不再赘述了。
- 我们面临的主要问题是如何按照开闭原则最小修改的对这次的程序迭代开发:
- 这一次的博客主要是向大家展示架构,就不做过多的细节论述了。
迭代需求实现的细节
函数调用函数的问题
- 我先实现函数调用调用自定义函数的问题
- 关键还是在DefFunc类中也实现substitute的方法。(这应该是这个接口的共同的方法,
- 但是我们不需要对Def类中的实参也进行实参的替换,因为在构造DefFunc时,我就已经将其中的函数全都替换成了表达式,所以我们要做的工作仅仅只是调用Expr.substitute()!非常的简单。
- 所以这样,在函数定义完之后,函数类的核心的属性是它展开后的表达式,函数定义表里面就不会出现嵌套函数这个东西了(皮都展开了,什么叫做远见明察呀
1 | public Factor substitute(HashMap<String, Factor> varMap) { |
求导的实现
- 我认为求导的实现和函数调用相似,每个类里都有一个求导的方法derivate()(但是具体实现上有点区别,比如考虑到Term的乘法求导法则,我们让它的derivate方法返回一个ArrayList< Term >
- 然后像函数调用一样递归的调用求导方法,解析展开成一个表达式
- 不要想把DefFunc这种的derivate的返回值设成表达式因子,没必要,返回自己怎么啦。
- 不要考虑覆写的问题,本来就是一种转换,本来后面不需要用到原版,本来就是一种覆写。
- 最后都要toPoly,反倒是返回表达式因子会让你在debug的时候十分的难受。
- 最后的重担落在了幂函数和三角函数的身上,为了实现链式求导法则以及幂函数求导的常数等需求,我们使Factor的derivate方法返回Term。
1 | public interface Factor { |
- 一定要注意链式法则与乘法法则的深克隆问题,不然连着给你改了。
结构上的统一性解读
- 所以其实在结构里,DefFunc,ExprFactor,Deriv都是统一的,他们内部都有一个Expr属性,除了生成方法不一致之外,其他都可以比较趋同的实现。对于DefFunc和Deriv我在构造的时候已经做好了表达式的展开,保证方法来的时候我的表达式已经准备好了。
- (结构中已经有了两种趋同,一种是求导方法和代入方法的趋同(生成方法上的趋同),另一种是上述三个类在结构实现上的趋同
- 第三种趋同是链式求导法则数学的统一性上,不需要特判是否有指数,表达式因子三角函数因子和变量因子按照链式法则求的方法是有一致性的。
1 | public Term derivate(String varName) { |
> 但是我有一个问题,链式求导法则的方法大致趋同,需不需要单独设立一个链式法则求导的方法呢,欢迎在评论区探讨!
这次的自动化评测机也只是在前两代的基础上小改一下下,所以就不说了。
三次迭代架构的度量分析
码量上
- 首先最为直观的肯定是代码行数上的变化,反映了代码的规模,类的规模。(首先声明每次作业的代码风格分都是满分
- 请见下表:
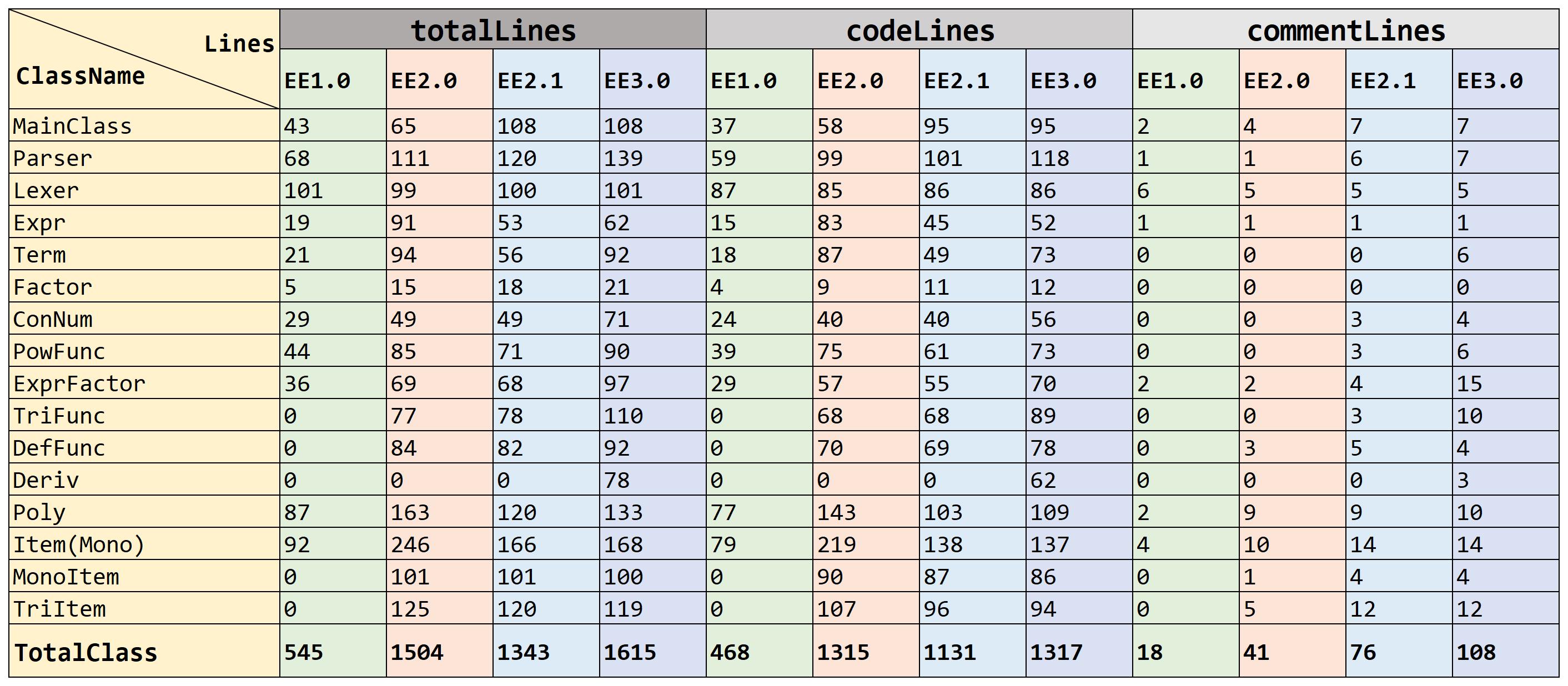
- 首先可以看到,我用浅红色标出的EE2.0(ExprExpansion),代码的长度极其的灾难,其中Item类更是达到了250行左右,但是经过优化之后的EE2.1代码行数上正常了许多。
- 最后的码量落到了1300左右。
复杂度上
- 然后就是方法的复杂度分析(只选取了部分关键的方法以及复杂度超标的方法)
- 下面是对指标的解释:
CogC 是圈复杂度的意思,与下面的v(G)一样
v(G) 是圈复杂度,表示程序中独立路径的数量,也就是测试程序所需的最少路径条数。圈复杂度越大,说明程序越复杂,越容易出错,越难测试和维护。
iv(G) 是模块设计复杂度,表示程序中结构化程度的高低。模块设计复杂度越大,说明程序越不符合结构化设计原则,越难理解和修改。
ev(G) 是基本复杂度,表示程序中非结构化成分的多少。非结构化成分指的是那些不遵循顺序、选择、循环三种基本控制结构的语句或语句块。基本复杂度越大,说明程序越不规范,越降低了代码质量和可读性。
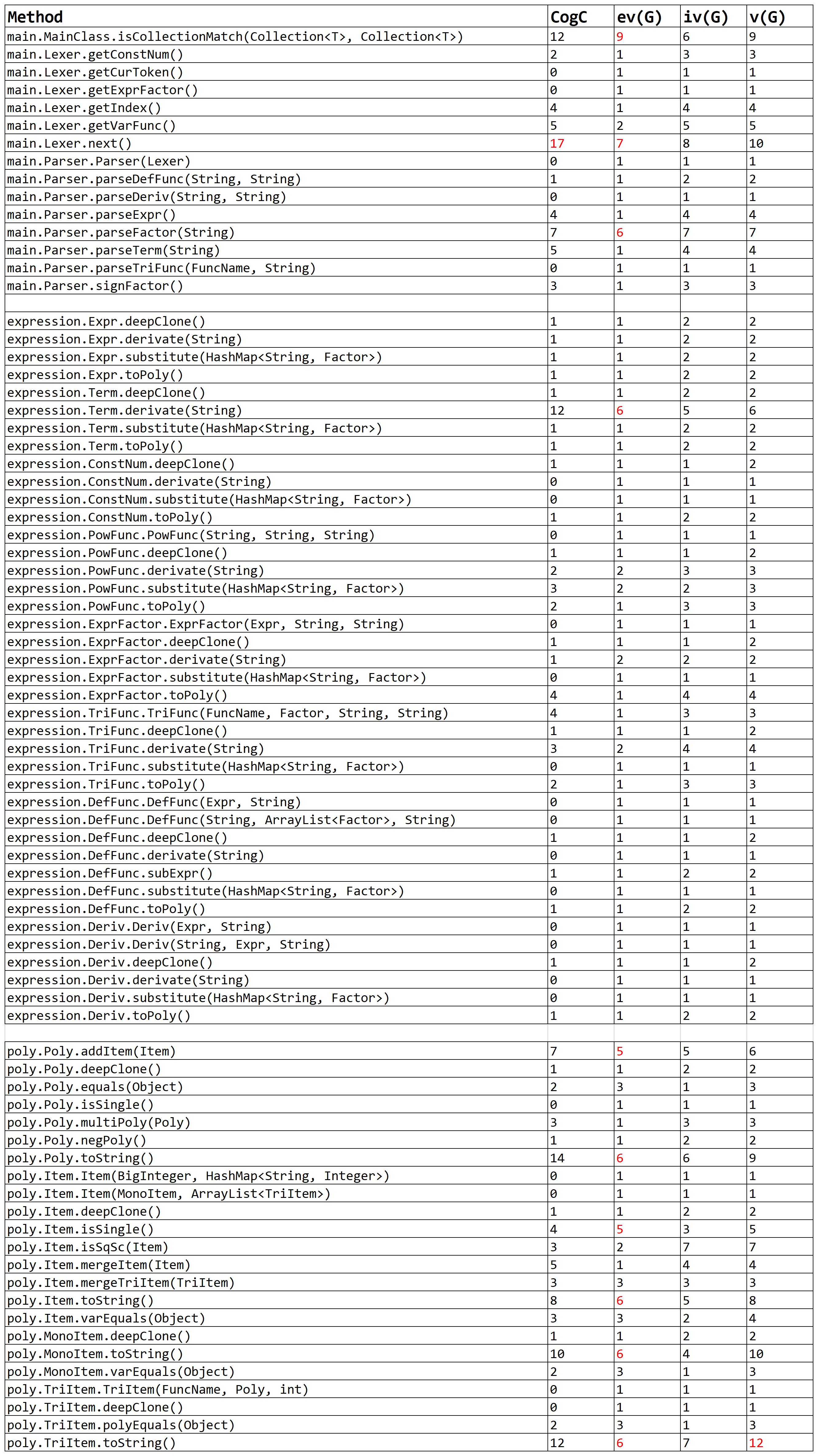
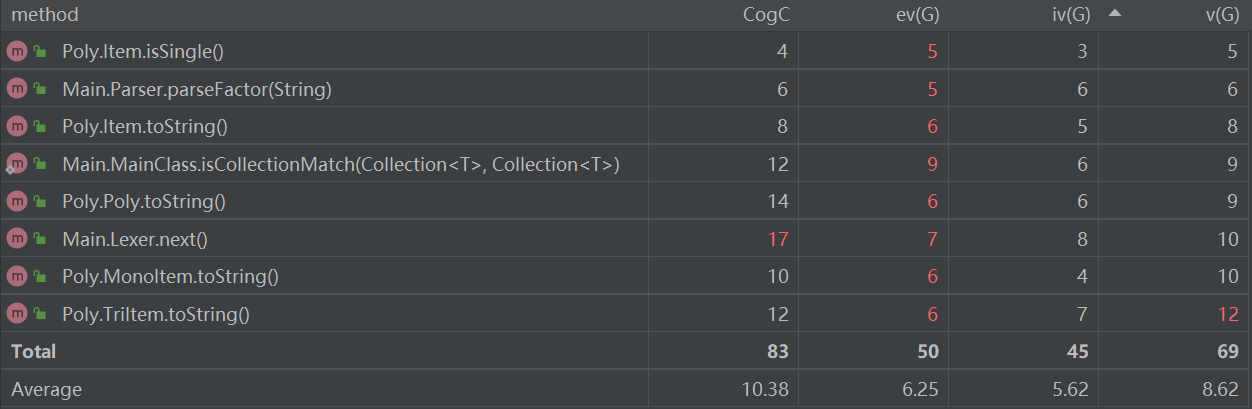
- 下面是EE3.0中复杂度超标的部分:
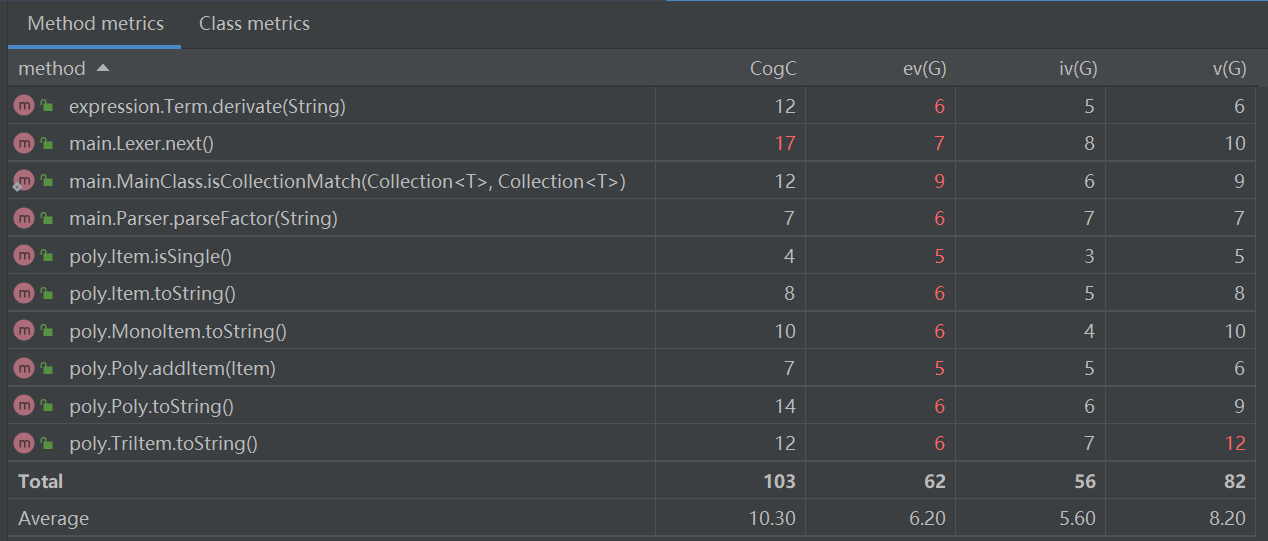
- 我们可以看到,对于圈复杂度,只有Lexer.next()方法与TriItem.toString()超标,
- 对于next()的方法实现,因为我是一次输出一个相对完整的字符串,所以我需要调用其他的一些方法来达成模块化设计的需求。
- 而对于TriItem.toString()的方法中,我为了许多细节的化简优化,比如说输出括号、去除符号等,打了许多的特判,所以圈复杂度会很高。
- 但是可以看到,许多方法的基本复杂度还是挺糟糕的,这也说明了我的代码质量与风格确实有比较大的问题(这也导致了EE2.0的缺陷),接下来还是得在这一方面多下功夫。
- 可喜的是我的模块设计复杂度都比较的良好,这也得益于良好的架构与合适的方法属性设置。