
北航面向对象与程序设计课程作业,表达式展开Expr-expansion 2.0,对1.0的迭代开发。
新增需求:嵌套括号,三角函数,自定义函数
BUAA-OO hw2
新增需求
- 多层括号(已完成
- 三角函数因子
- 自定义函数因子,自定义函数不会复合(但是要做好迭代的准备
形式化表述
表达式 → 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
项 → [加减 空白项] 因子 | 项 空白项 ‘*‘ 空白项 因子
因子 → 变量因子 | 常数因子 | 表达式因子
变量因子 → 幂函数 | 三角函数 | 自定义函数调用
常数因子 → 带符号的整数
表达式因子 → ‘(‘ 表达式 ‘)’ [空白项 指数]
幂函数 → 自变量 [空白项 指数]
自变量 → ‘x’ | ‘y’ | ‘z’
三角函数 → ‘sin’ 空白项 ‘(‘ 空白项 因子 空白项 ‘)’ [空白项 指数] | ‘cos’ 空白项 ‘(‘ 空白项 因子 空白项 ‘)’ [空白项 指数]
指数 → ‘**‘ 空白项 [‘+’] 允许前导零的整数 (注:指数一定不是负数)
带符号的整数 → [加减] 允许前导零的整数
允许前导零的整数 → (‘0’|’1’|’2’|…|’9’){‘0’|’1’|’2’|…|’9’}
空白项 → {空白字符}
空白字符 → (空格) | \t
加减 → ‘+’ | ‘-‘
自定义函数定义 → 自定义函数名 空白项 ‘(‘ 空白项 自变量 空白项 [‘,’ 空白项 自变量 空白项 [‘,’ 空白项 自变量 空白项]] ‘)’ 空白项 ‘=’ 空白项 函数表达式
自定义函数调用 → 自定义函数名 空白项 ‘(‘ 空白项 因子 空白项 [‘,’ 空白项 因子 空白项 [‘,’ 空白项 因子 空白项]] ‘)’
自定义函数名 → ‘f’ | ‘g’ | ‘h’
函数表达式 → 表达式 (注:本次作业中函数表达式保证不会调用自己或其他自定义函数)
老规矩,空白字符对我们已经构不成威胁,所以我们去除空白字符,然后去除基元,简单表示。
下面是省流版的形式化表示(与上次的不同已加粗)
Expr -> [±] Term | Expr ‘±’ Term
- Term -> [±] Factor | Term ‘*‘ Factor
- Factor -> Variable | ConNum | ExprFactor
- Variable-> PowFunc | TriFunc | DefFunc
- PowFunc -> indepVar index
- ConNum -> [±] Num
- ExpFac -> ‘(‘ Expr ‘)’ index
- TriFunc -> ‘sin’ ‘(‘ Factor ‘)’ index | ‘cos’ ‘(‘ Factor ‘)’ index
DefFunc -> (‘f’|’g’|’h’) ‘(‘ Factor[\times 3] ‘)’
- (‘f’|’g’|’h’) ‘(‘ indepVar[\times 3] ‘)’ = Expr
Num -> ( 0 ~ 9 ) { 0 ~ 9 }
- indepVar-> (‘x’ | ‘y’ | ‘z’)
- index -> [‘**‘ [‘+’] Num]
分析需求&坑点汇总
- 展开括号以及自定义函数
- 尽可能短
关于三角函数
- 三角函数里的x**2一定要注意,如果直接修改为x*x要加括号,但是显然不好。
- 就是说要注意TriFunc里面是Factor
- 三角函数除了展开内部的因子外,如何化简?
- 三角函数:
- 判断相等:
- 重载hashcode比较。
- 判断因子的poly相等。
- 字符串排序对比。
- 化简:
- cos(0),sin(0)
- 同类项合并。
- 平方项合并。(博主没时间做,只实现了最简单的合并)
- 倍角合并
- 先都把倍角展开成一倍角,再进行合并,最后进行化简
- cos里有个负号可以省去,注意cos(-1), cos((-1))的不同
- 判断相等:
关于函数定义与调用
- 怎么储存函数的定义?存字符串还是存表达式?
- 怎么解决函数的调用问题,需要一个新的函数类,在构造的时候解决函数调用的问题?或者说在toPoly的时候解决掉调用的问题?
- 函数:
- 定义:正则表达式分成两份。一份字符串处理,另一份表达式打表储存。
- 在处理函数定义的时候,只记录形式参数的位置,就用uvw替换掉乱序的xyz。(可以这么去考虑,也可以建立起形参实参彼此之间的关系
- 调用:
- 方法一:字符串替换,但是得加上括号作为表达式,兼顾x**2中用y**2替换x的问题(我不是这么实现的,不丁真,而且不推荐
- 方法二:扫到形参调用实参的Factor,每个类都加上substitute的方法,递归调用,最后都把自变量替换为表达式因子(也不一定是表达式因子,可以有其他的调用)。
- 定义:正则表达式分成两份。一份字符串处理,另一份表达式打表储存。
具体实现
uml类图及简述
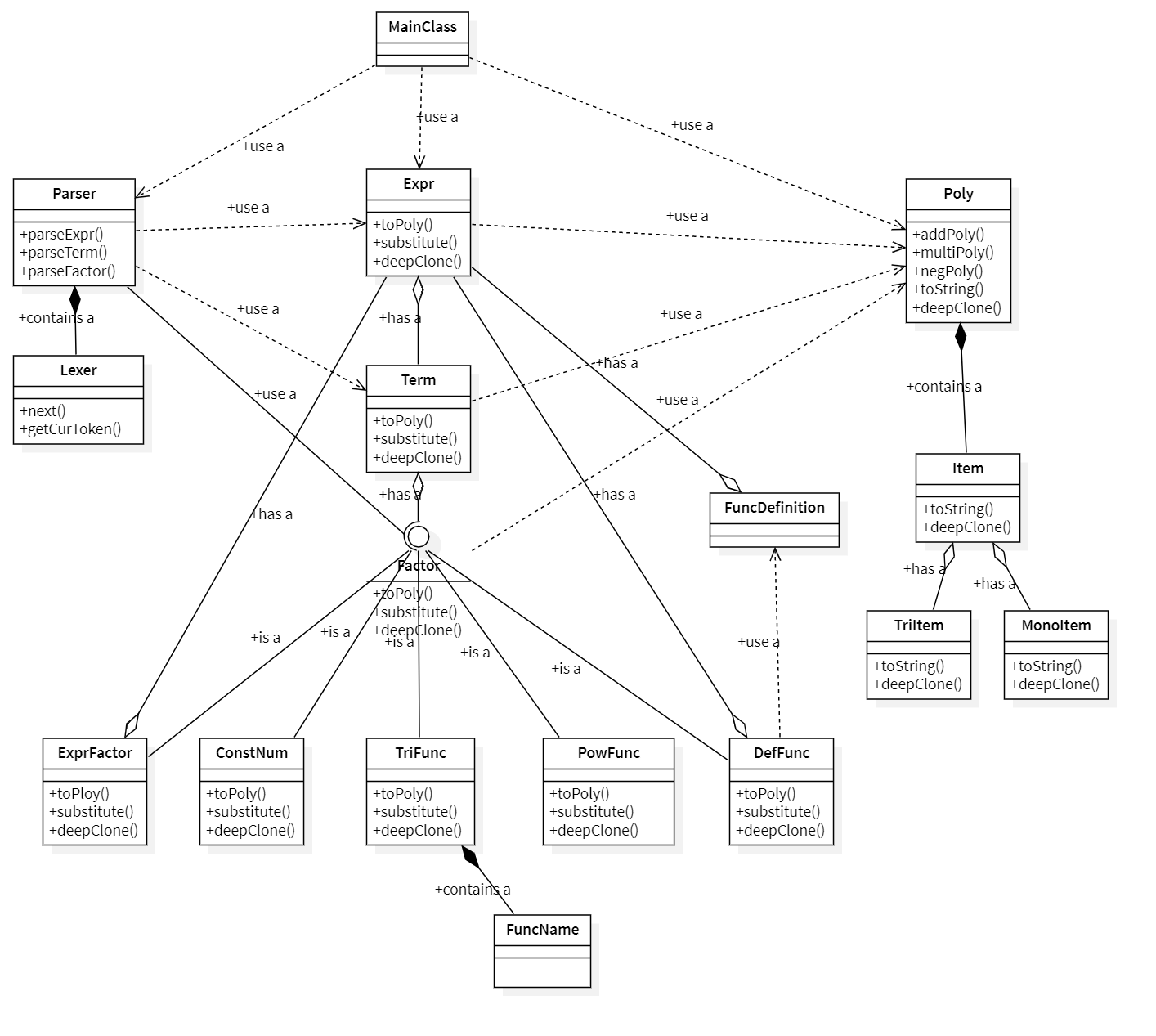
- 以上是我本次作业的类图(只放出了核心的方法与关系
- 我继承自第一次作业的架构,其中分为了三个纵向的层次结构,parse层次,Expr层次,Poly层次
- 其中比较亮点的地方在于toPoly,toString,substitute,deepClone等方法,我均通过上层调用下一层的递归实现,体现了层次化的思想。
- 具体细节请看下文。
需求实现
- 首先要强调的一点仍然是parser的实现,我们需要规定调用时,lexer指在要处理位置;退出调用时,lexer停在处理完的位置(Term调因子的时候)。这样在能过统一上层调用的实现。
- 然后就是在Expr类的设置上,我新增DefFunc类与TriFunc类实现Factor的接口(注意虽然在形式化的表述上Factor是他俩的爷爷辈,但是Variable符号并没有被整体引用过,所以让他俩直接实现Factor也是一样的)
- 然后就是关于Poly类的兼容问题,第二次作业中新增了三角函数类,所以Poly的最终形式中会多出来三角函数的item所以我将Mono改名Item,并将其一分为二,下设MonoItem与TriItem,但是他们内部的权限开到最高,只是为了方便输出与合并而已(做出了一个违背祖宗的决定。
- 化简的最终形式应该是 $\Sigma ConNumx^ay^bz^c\Pi \sin(Factor)^{d_i} * \Pi \cos(Factor)^{e_j} $ 所以Item的属性如下:
1 | //item的属性 |
- 下面具体实现三件事:
- 函数定义与调用,深克隆,三角函数化简
函数定义与调用的实现
- 函数定义,新建静态类FuncDefinition
- 睿睿说:在函数定义的时候把第一二三个位置的形参都换成u,v,w,这样我就不需要考虑实参和xyz的对应关系了
- 俺觉得很有道理。
- 但是要直接字符串替换要考虑后续迭代中的冲突问题,如果后续添加的函数中包含xyz,uvw等字符,那就需要换或者另找办法了
- 所以为了可拓展性,我还是修改了策略,传入实参后,弄一个hashmap形成形参实参的映射。
- 而关于存字符串还是存表达式的问题,由于我的函数调用的实现是substitute()方法的递归调用替换,另外为了性能效率(每一次用表达式还得重新Parse一遍),构造Def对象时就展开成表达式。后续直接调用即可(但是得注意深克隆,毕竟静态函数表中的表达式我们不可以去改变他)。
- 睿睿说:在函数定义的时候把第一二三个位置的形参都换成u,v,w,这样我就不需要考虑实参和xyz的对应关系了
- 关于函数调用:
- 要代入的话,Expr这些类就需要对外提供查询修改的接口,要尽量对外隐藏细节,我只能把形参传入,然后递归的调用下去了。我在每个类都设置了substitute的方法,递归调用,直到Factor层面(Factor有返回值Factor),遇到在实参形参映射表中的变量就替换(所以我们知道调用的叶节点就是PowFunc和ConNum)
- 关于调用的返回值,可以一劳永逸的套个带指数的ExprFactor(但是这样会增加递归调用层数,增大代价以及debug的难度),也可以分情况返回不同的Factor,如下
1 | //可以分情况写成: |
关于深克隆的实现
- 深克隆很重要,函数调用一定要使用深克隆,所以我们需要在类中提前实现深克隆的方法
- 不过深克隆也可以采取递归的结构来克隆类中的每一个属性。
- 最后的叶节点也会是PowFunc与ConNum。
- 相信不会很难,按部就班写好即可。
三角函数的存放与化简
- 先写出toPloy的方法。
- 然后需要写一个判断Poly相等的方法,来实现三角函数合并。
- 判断因子相等,有两个方法,一个是调用factor.equals,另一个是调用Poly.equals
- equals的方法也是递归的实现。
- 若加入三角函数化简公式,在addpoly与multipoly中改即可(item中处理维度不高)。可以添加item中的方法使poly获取到mono|tri的信息然后判断是否可以合并。
- 判定三角函数里是否需要括号的准则是不出现不在poly.toString首的正负号,可以用字符串匹配
- 但是有误,后来换成判断Poly中的元素个数(更加的可靠
自动化测试
- 第二次作业这一周太忙了,本来不打算弄自动化测试的,但是得到了睿睿的帮助(大家可以移步友链toby’s Bolg),睿睿负责了评测,我设计了数据生成器。
- 第二次的数据生成器并不能像第一次那样无脑的随机递归下降,如果这样,生成的数据的复杂度直接起飞,但是又不能卡定生成概率,让数据变得很弱。
- 所以我有一点核心设计是增加了一个(或者几个)全局的难度指标,随着难度的增加去影响不同分支的生成概率。设计示意如下:
1 | ran_num = random.random() |
- 另外还有用全局标记来影响下一个生成分支中的生成概率的设计,这主要解决的是,函数定义的复杂度与表达式的复杂度之间有差异,函数调用的实参因子的复杂度不宜过高的这些问题。设计的大致示意如下:
1 | expr_used = True |
第二次作业的问题总结
- 在第二次作业的这一周里,博主忙东忙西,每天睡眠时间平均4小时不到,其中OO的代码我熬了一晚上优化,但是优化坏了,而且代码风格遭到了严重的破坏(这告诉我们一定要规律作息,不要熬夜打代码!!!
- 不过我也感谢我急急忙忙的第二次作业的经历,在第二次的跨越式迭代之后,我对于层次化的理解又更近了一步。并且我在第二次作业过后再来审视我的石山代码,得到了不少的教训。
- 优化了许多,最后形成了ExprExpansion2.1(EE2.1),具体请看下一次博客。

