
BUAA-CO课程p6,在p5的基础上,增加一些基础指令,IM、DM外置,增加乘除模块等
p6_log
p6在p5的基础上进行改进,除了加指令外,有几点改动
通过output传出相应信号不再使用$display
IM,DM外置只留下相应接口
但需要实现单独的乘除法模块和数据拓展模块
设计思路-纲领
摘要
- 我们先通过对于RTL构造出无需转发的数据通路表
- 在考虑转发的情况构造出转发的数据通路
搭建电路(图文结合)
然后逐条指令分析主控制器控制信号
- 逐条指令分析 $T_{use}, T_{new} $
- 构造策略矩阵
写控制表达式
这是一个自下而上的过程
- 可以先实现p5所需的基础指令
然后对于MIPS-C3架构指令集增量开发
最后构建自动化测试与样例生成器
实现指令
- 对于指令的分类很重要
- 下面是所需要是实现的指令类和指令
- 寄存器寄存器计算:add, sub, and, or, slt, sltu, xor
- 寄存器立即数计算:addi, andi, ori, slti, xori
- 位移类: sll, srl, sra, sllv, srlv, srav
- B类:beq, bne
- store:sw, sh, sb
load:lw, lh, lhu, lb, lbu
跳转并链接:jal, jalr, j
- 跳转寄存器:jr, jalr
- 加载高位:lui
- 空指令:nop
- 读乘除法寄存器:mfhi, mflo
写乘除法寄存器:mult, multu, div, divu, mthi, mtlo
p5要求实现的基础指令有:add, sub, ori, lw, sw, beq, lui, jal, jr, nop
命名规范
- 在控制信号连线名末尾加上_阶段字母,如:NPCOp_D,用以区分所属阶段
- 在寄存器输出信号前加上阶段字母_, 如:D_A1,用以区分所属阶段
- 功能部件输出信号前加上功能部件.,(实际打码时舍弃)
- MUX命名采取X_输入端口名_选择数
- 转发MUX命名采用F_输入端口名_选择数,级数越大优先级越高
模块设计
数据通路
数据通路表
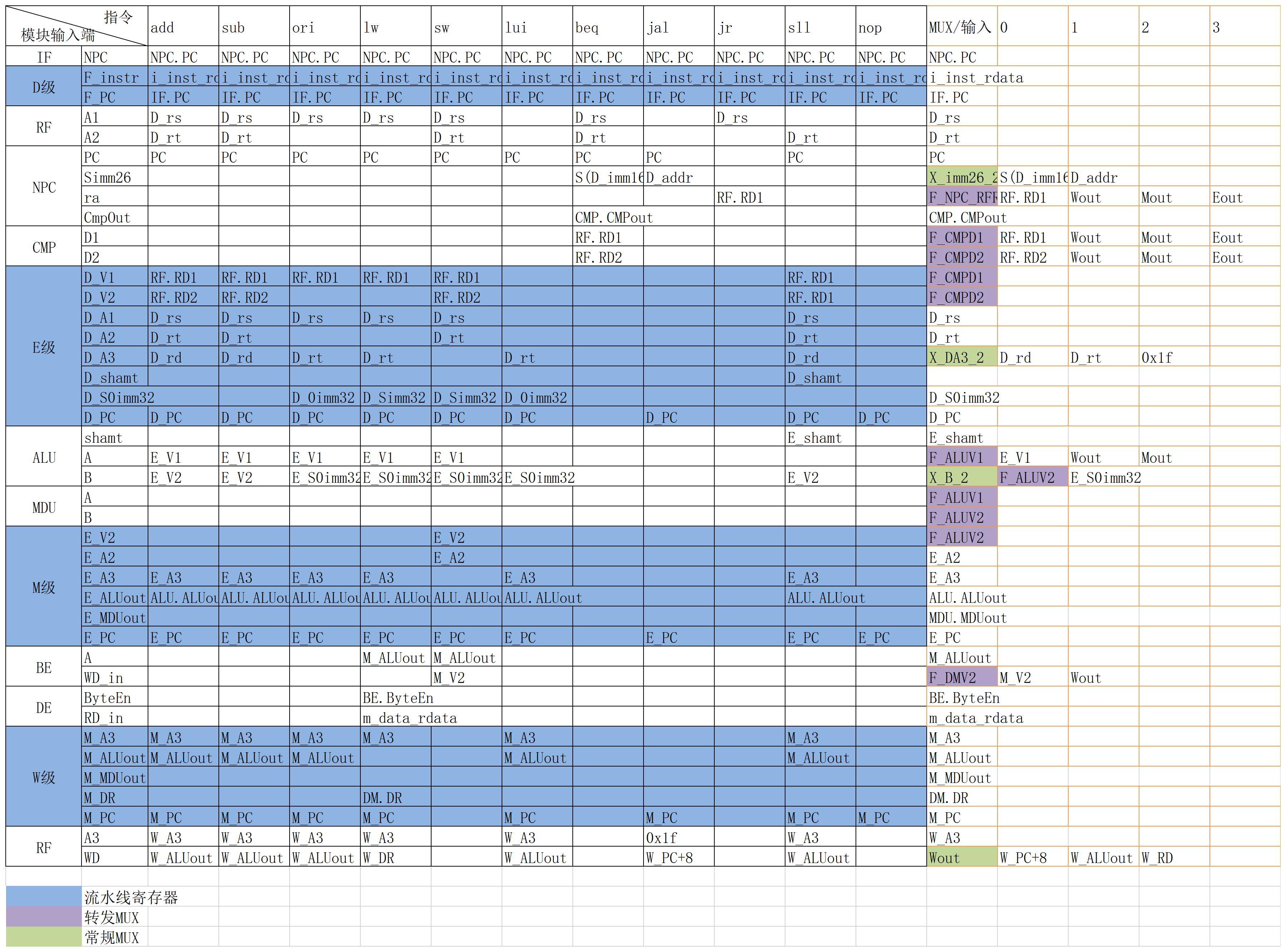
功能模块
IFU(PC\IM)
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| en | I | 使能 | 暂停时使用 |
| NPC[31:0] | I | 由NPC返回,下一条指令的PC | |
| PC[31:0] | O | 当前执行的指令地址 |
RF
- 内部转发
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| WE | I | 写使能信号 | |
| A1[4:0] | I | 读出地址1 | |
| A2[4:0] | I | 读出地址2 | |
| A3[4:0] | I | 写入地址 | |
| WD[31:0] | I | 写入的数据 | |
| RD1[31:0] | O | 输出A1地址寄存器中的值 | |
| RD2[31:0] | O | 输出A2地址寄存器中的值 |
CMP
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| D1[31:0] | I | 待比较数据1 | |
| D2[31:0] | I | 待比较数据2 | |
| CMPOp[2:0] | I | CMP功能选择:</br> 000: beq </br> 001: bne </br> 010: blez </br> 011: bgtz | |
| out | O | 结果为1则分支跳转,为0不跳转 |
NPC
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| PC[31:0] | I | 当前指令地址 | |
| Simm26[25:0] | I | 地址偏移 | |
| ra[31:0] | I | 返回地址 | |
| CmpOut | I | B类指令的比较结果 | |
| NPCOp[2:0] | I | NPC功能选择:</br> 000: 顺序+4 </br> 001: B类跳转 </br>010: jal/j </br> 011:jr/jalr | |
| NPC[31:0] | O | 下一条指令地址 |
EXT
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| imm16[15:0] | I | 16位立即数 | |
| EXTOp | I | EXT功能选择:</br> 0: 0拓展 </br> 1: 符号位拓展 | lui指令的高位拓展在ALU里执行 |
| S0imm32 | O | 拓展后的32位立即数 |
ALU
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| ALUOp[3:0] | I | ALU功能选择 | 具体对于功能后有附录 |
| A[31:0] | I | 运算数1 | |
| B[31:0] | I | 运算数2 | |
| shamt[4:0] | I | 位移值 | |
| ALUout[31:0] | O | 计算结果 |
MDU(乘除模块)
- 给M,W级的out中加上MDUout
- busy阻塞实现:将busy和start_E,MDUOP_D接入HCU
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| start | I | 开始运算信号 | |
| MDUOp[3:0] | I | 乘除模块功能选择信号 | 见附录 |
| A[31:0] | I | 运算数1 | |
| B[31:0] | I | 运算数2 | |
| Busy | O | 乘除法延迟符 | |
| HI[31:0] | O | HI寄存器输出值 | |
| LO[31:0] | O | LO寄存器输出值 | |
| MDUout[31:0] | O | MDU输出(HI \ | LO) |
- 功能选择信号定义
| MDUOp[3:0] | 描述 |
|---|---|
| 0000 | nop(相当于不使能) |
| 0001 | mult |
| 0010 | multu |
| 0011 | div |
| 0100 | divu |
| 0101 | mfhi |
| 0110 | mflo |
| 0111 | mthi |
| 1000 | mtlo |
DM
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| WE | I | 写使能信号 | |
| A[31:0] | I | 待操作数据的地址 | |
| WD[31:0] | I | 待写入的数据 | |
| DMOp[2:0] | I | DM功能选择:000: word </br> 001: halfword </br> 010: byte </br> 1xx: 无符号拓展load | 最高位置一表示无符号位拓展 |
| DMout[31:0] | O | 输出的32位数据 |
BE
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| A[31:0] | I | DM写入地址 | |
| DMOp[2:0] | I | DM功能选择:000: word </br> 001: halfword </br> 010: byte </br> 1xx: 无符号拓展load | 最高位置一表示无符号位拓展 |
| WE | I | 写使能信号 | |
| WD_in[31:0] | I | 原始待写入数据 | |
| ByteEn[3:0] | O | 字节使能 | |
| WD_out[31:0] | O | 处理后写入数据 | 移动到相应的位置上,比如存入字节则8位以上全置位0 |
DE
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| A[31:0] | I | DM读出地址 | |
| RD_in[31:0] | I | 待处理DM读出数据 | |
| DMOp[2:0] | I | DM功能选择:000: word </br> 001: halfword </br> 010: byte </br> 1xx: 无符号拓展load | 最高位1表示无符号位拓展 |
| RD_out[31:0] | O | 处理后DM读出数据 |
流水线寄存器
- 每个流水线寄存器都保存着一条指令完成后续操作所需要的的全部信息。
- 对于每一个流水线的产生结果的级次,我需要用一个MUX来确定哪个是当前指令的用于转发的有效数据,PC+8, ALUout,DMout,所以我们增加outSel的选择信号,此选择信号可以代替RFWDSel的功能
D(IF/ID)
- 可以在D级内置Splitter
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| en | I | 使能信号 | 暂停时置位0 |
| F_instr[31:0] | I | F级取出的指令 | |
| F_PC[31:0] | I | F级输出的指令PC | |
| D_opcode[5:0] | O | 当前D级的opcode | |
| D_rs[4:0] | O | rs | |
| D_rt[4:0] | O | rt | |
| D_rd[4:0] | O | rd | |
| D_shamt[4:0] | O | 偏移量,位移指令使用 | |
| D_funct[5:0] | O | funtion码 | |
| D_imm16[15:0] | O | 16位立即数 | |
| D_address[25:0] | O | 26位地址 | |
| D_PC[31:0] | O | D级当前指令地址 |
E(ID/EX)
- 从E级开始流水控制信号
- T_new-1
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | 暂停时置为1 |
| en | I | 使能信号 | |
| [31:0] D_V2 | I | ||
| [4:0] D_A1 | I | ||
| [4:0] D_A2 | I | ||
| [4:0] D_A3 | I | ||
| [4:0] D_shamt | I | ||
| [31:0] D_S0imm32 | I | ||
| [31:0] D_PC | I | ||
| ALUOp_D[3:0] | I | ||
| DMOp_D[2:0] | I | ||
| RFWE_D | I | ||
| DMWE_D | I | ||
| BSel_D | I | ||
| outSel_D[1:0] | I | ||
| RFWDSel_D[1:0] | I | ||
| T_new_D[1:0] | I | ||
| [31:0] E_V1 | O | ||
| [31:0] E_V2 | O | ||
| [4:0] E_A1 | O | ||
| [4:0] E_A2 | O | ||
| [4:0] E_A3 | O | ||
| [4:0] E_shamt | O | ||
| [31:0] E_S0imm32 | O | ||
| [31:0] E_PC | O | ||
| ALUOp_E[3:0] | O | ||
| DMOp_E[2:0] | O | ||
| RFWE_E | O | ||
| DMWE_E | O | ||
| BSel_E | O | ||
| outSel_E[1:0] | O | ||
| RFWDSel_E[1:0] | O | ||
| T_new_E[1:0] | O |
M(EX/MEM)
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| en | I | 使能信号 | |
| [31:0] E_V2 | I | ||
| [4:0] E_A2 | I | ||
| [4:0] E_A3 | I | ||
| [31:0] ALUout | I | ||
| [31:0] E_PC | I | ||
| DMOp_E[2:0] | I | ||
| RFWE_E | I | ||
| DMWE_E | I | ||
| outSel_E[1:0] | I | ||
| RFWDSel_E[1:0] | I | ||
| T_new_E[1:0] | I | ||
| [31:0] M_V2 | O | ||
| [4:0] M_A2 | O | ||
| [4:0] M_A3 | O | ||
| [31:0] M_ALUout | O | ||
| [31:0] M_PC | O | ||
| DMOp_M[2:0] | O | ||
| RFWE_M | O | ||
| DMWE_M | O | ||
| outSel_M[1:0] | O | ||
| RFWDSel_M[1:0] | O | ||
| T_new_M[1:0] | O |
W(MEM/WB)
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| clk | I | 时钟信号 | |
| reset | I | 同步复位 | |
| en | I | 使能信号 | |
| [4:0] M_A3 | I | ||
| [31:0] M_ALUout | I | ||
| [31:0] M_DR | I | ||
| [31:0] M_PC | I | ||
| RFWE_M | I | ||
| outSel_M[1:0] | I | ||
| RFWDSel_M[1:0] | I | ||
| T_new_M[1:0] | I | ||
| [4:0] W_A3 | O | ||
| [31:0] W_ALUout | O | ||
| [31:0] W_DR | O | ||
| [31:0] W_PC | O | ||
| RFWE_W | O | ||
| outSel_W[1:0] | O | ||
| RFWDSel_W[1:0] | O | ||
| T_new_W[1:0] | O |
控制模块
- 此CPU采用集中译码的方式,在D级译码,控制信号进入流水,使用过的就不用进入了
- T_new产生后随着流水线递减
- 分为MCU,HCU
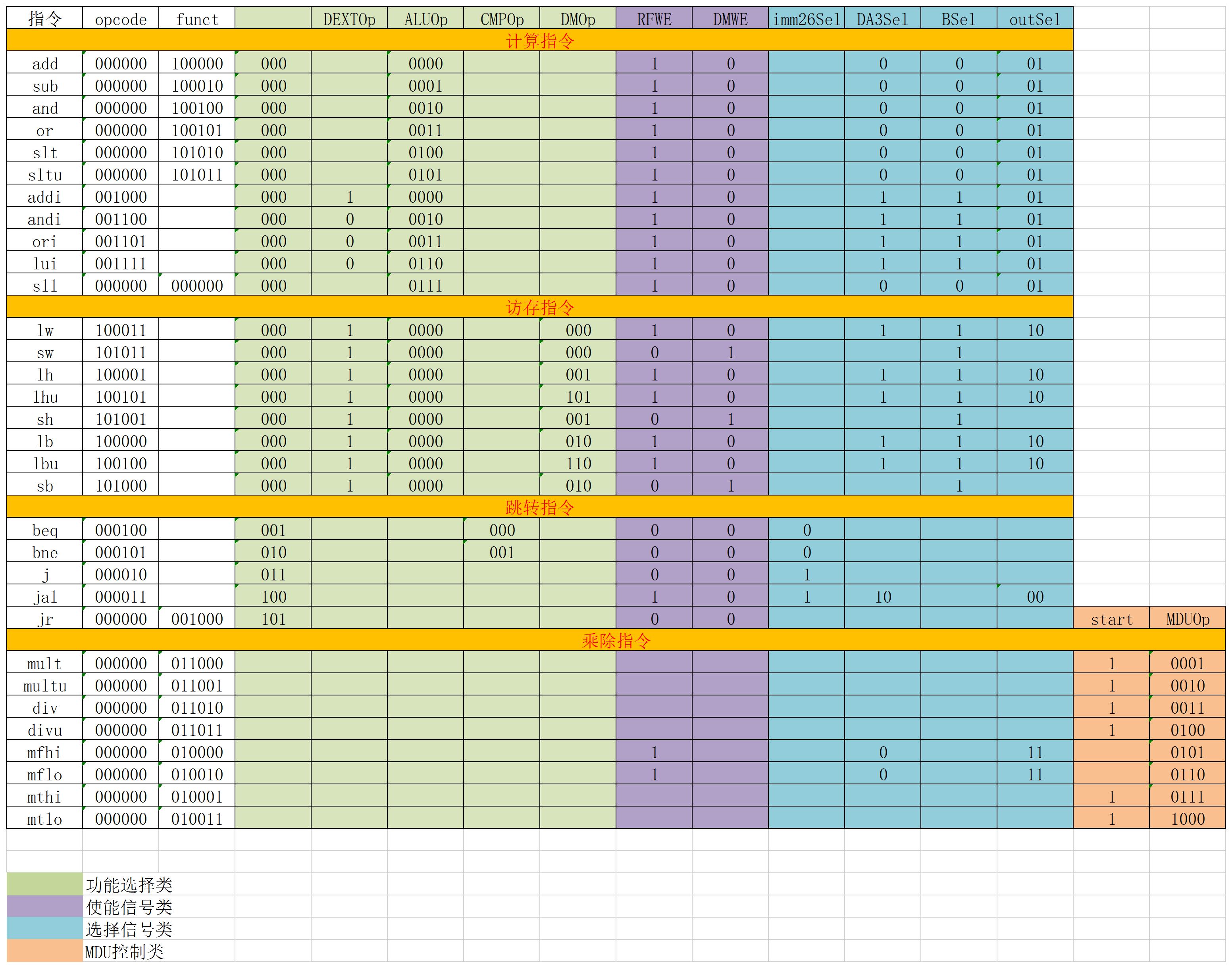
主控制器(MCU)
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| opcode[5:0] | I | D_opcode | |
| funct[5:0] | I | D_funct | |
| NPCOp_D[2:0] | O | ||
| ALUOp_D[3:0] | O | ||
| DEXTOp_D | O | ||
| DMOp_D[2:0] | O | ||
| RFWE_D | O | ||
| DMWE_D | O | ||
| imm26Sel_D | O | ||
| DA3Sel_D[1:0] | O | ||
| BSel_D | O | E_ALU_B信号选择:{} | |
| RFWDSel_D[1:0] | O | ||
| outSel_D[1:0] | O | 有效转发数据Sel | |
| MDUOp_D[3:0] | O | ||
| start_D | O | ||
| T_rsUse[1:0] | O | 当前指令用到rs寄存器所剩下的时间 | |
| T_rtUse[1:0] | O | rt | |
| T_new_D[1:0] | O | 当前指令产生结果所需的时间 |
- MUX控制信号的具体含义可以看数据通路表
冒险控制器(HCU)
- 空行表示逻辑与功能上的分割
- 我这里只需要D级输出T_use因为我只有stall需要用到T_use,而stall应只在D级就决定,转发只需判断Tnew==0
| 信号名 | IO | 描述 | 备注 |
|---|---|---|---|
| D_A1[4:0] | I | ||
| D_A2[4:0] | I | ||
| E_A1[4:0] | I | ||
| E_A2[4:0] | I | ||
| M_A2[4:0] | I | ||
| E_A3[4:0] | I | ||
| M_A3[4:0] | I | ||
| W_A3[4:0] | I | ||
| RFWE_E | I | ||
| RFWE_E | I | ||
| RFWE_E | I | ||
| Busy | I | ||
| MDUOp[3:0] | I | ||
| start_E | I | ||
| T_rsUse[1:0] | I | D级MCU输出T_use | |
| T_rtUse[1:0] | I | D级MCU输出T_use | |
| T_new_E[1:0] | I | ||
| T_new_M[1:0] | I | ||
| T_new_W[1:0] | I | ||
| RFRD1Fwd[1:0] | O | NPC读入RA的转发 | |
| CMPD1Fwd[1:0] | O | D_RD1的转发 | |
| CMPD2Fwd[1:0] | O | D_RD2的转发 | |
| ALUV1Fwd[1:0] | O | ALU_A的转发 | |
| ALUV2Fwd[1:0] | O | ALU_B的转发 | |
| DMV2Fwd[1:0] | O | DM_WD的转发 | |
| stall | O | 暂停信号 |
- Sel结尾代表常规MUX信号,Fwd结尾代表转发MUX信号
- 转发MUX的Sel的含义大致是数字越大优先级越高,优先级是E、M、W
实现方法
访存指令
- 写好对应的BE、DE
跳转分支指令
- 要特别注意PC+8的转发问题,当检测到jal时转发
- 因为我是统一NPC模块,提供npc接口,所以NPC模块的pc输入得是F级的pc
- 所以要注意beq生效的时候接入的是下一条的pc,所以应该是
PC+Simm32而不用+4。
乘除指令
- MDU的AB端口都接入F_ALUV1,F_ALUV2(与ALU一致)
- 传入MDUOp判断指令
- 实现方法是在cnt结束之前一直用64位的tmp寄存器保存结果
- 除cnt—,和BusyReg置位以外全是组合逻辑的操作(不然可能会多出来一个空周期)
冒险处理
- 先根据每一条指令,整理其Tuse,Tnew
整理出指令的时间表
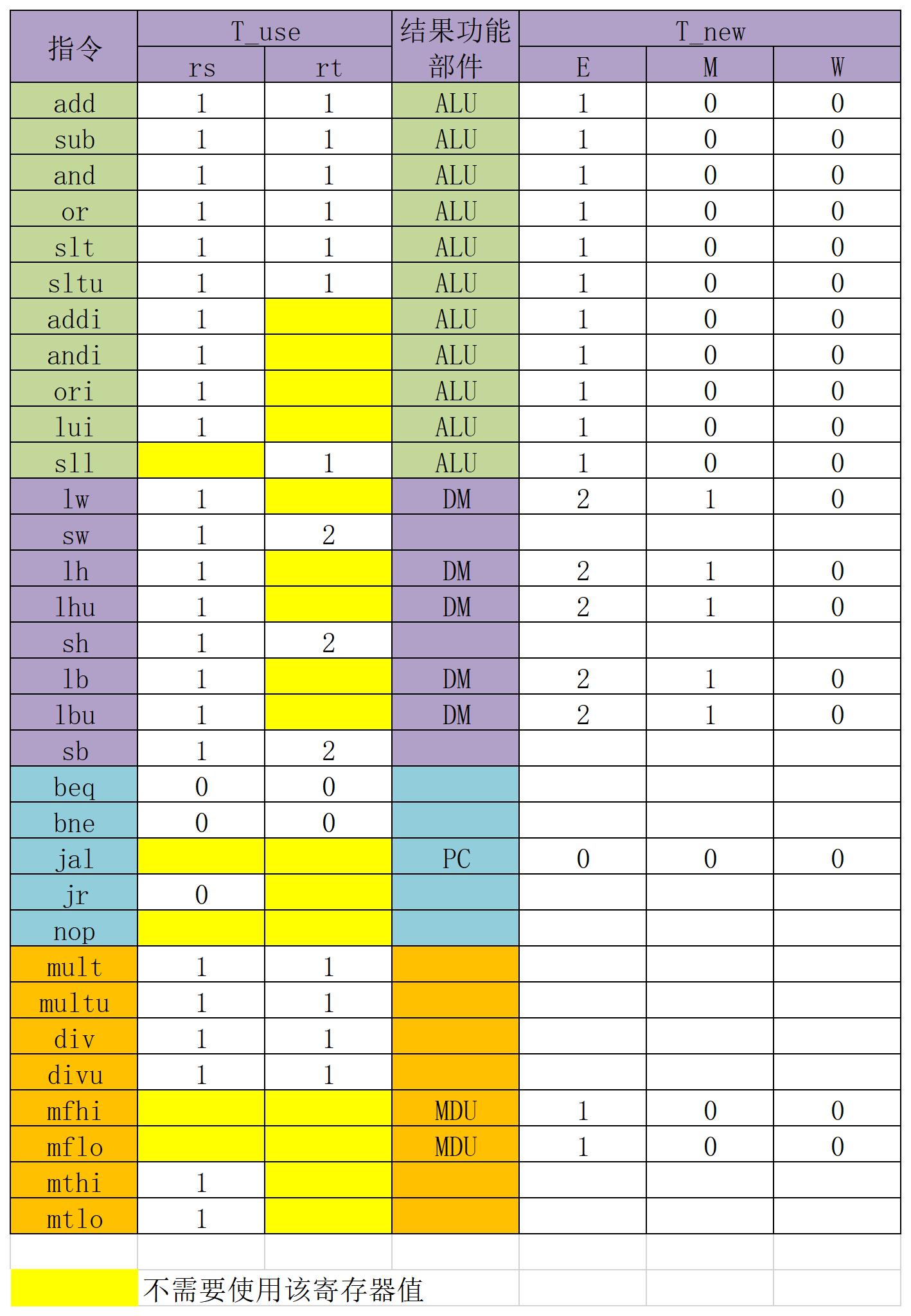
再根据每条指令的时间列出转发暂停控制信号表
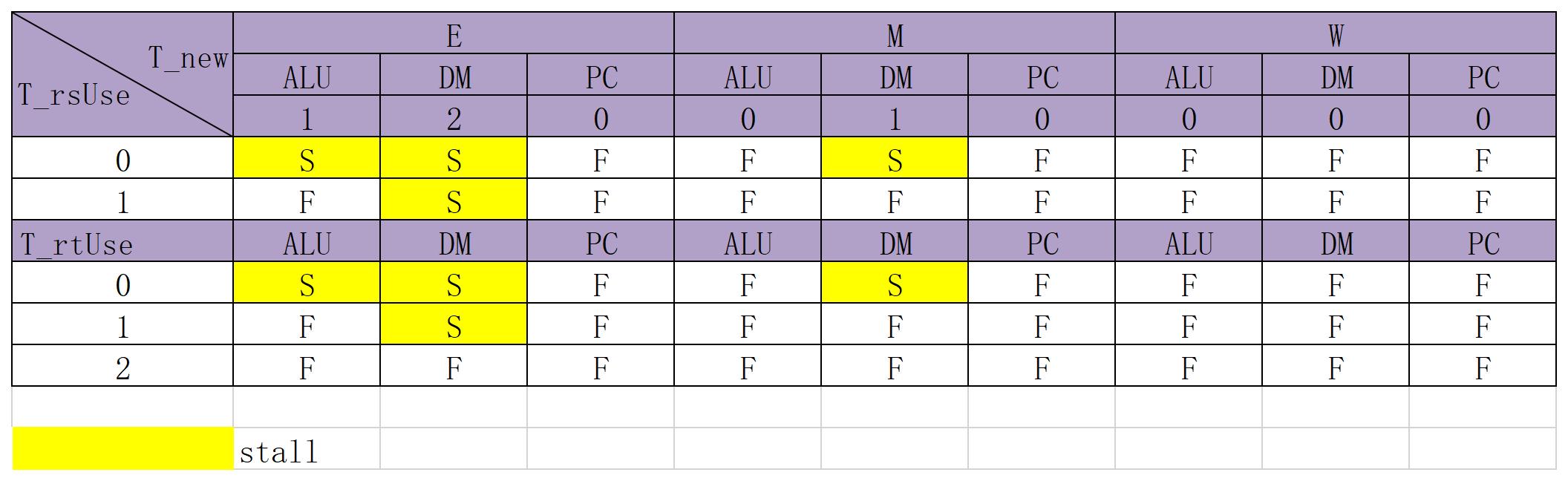
转发策略
- 遵循暴力转发策略,在打好常规的数据通路表后,观察哪些端口需要用到寄存器值(需求者),再把所有的供给者的情况遍历出来
- 可以适当增加转发条件,如T_new = 0
- AT法: 需求者是需要用这个值来运算的,找到所有与V,RD相关的端口;供给者是需要这个值来存入的,考虑它啥时候能够算出来。
- 我们把RFWE放入HCU用以保证写使能信号有效(有效数据)
- 判断A3!=0
- 转发要素:
- (A1(2) = A3)?
- $T_{new} = 0 $ ?
- RFWE = 1 ?
- A3 != 0 ?
- 转发机制:结果出来后都转发,只需改变控制信号。
- 代码如下:
1 | assign CMPD1Fwd = ((D_A1 == E_A3) & (T_new_E == 0) & RFWE_E & E_A3!=0)? `Eout : |
暂停策略
- 注意对于不要用的rt,rs要把T_use置位2(防止在i型指令的时候多暂停)
- 所以常规寄存器的暂停要素:
- $T_{use} < T_{new}$ 这在图表上对应了四种暂停情况,咱们枚举出来
- A1(2) = A3 ?
- RFWE = 1 ?
- A3 != 0 ?
- 代码如下:
1 | assign stall_rs0_E1 = (T_rsUse == 0) & (T_new_E == 2'b01) & (D_A1 == E_A3) & RFWE_E & E_A3!=0; |
- 对于乘除指令:
- 将Busy,start_E,MDUOp_D传入HCU
- 然后md暂停信号为
(Busy | start_E) & (MDUOp_D != 0)
- 暂停的机制:暂停D级,清空E级,暂停IF
测试数据及自动化测试
常规测试
- 基础指令的测试同p4
冒险测试
- 对于冲突进行覆盖性分析,需要我们根据冲突表,45种情况每一种都设计相应的冒险测试数据(建立在基础测试通过的情况下)
自动化
思考题
1、为什么需要有单独的乘除法部件而不是整合进 ALU?为何需要有独立的 HI、LO 寄存器?
- 乘除法都有较高的延迟,若整合进ALU,则进行乘除法的时候,所有的运算类指令都只能阻塞在D级,造成了极大的性能损失。单独设置MDU的话,无关的指令还能正常的在ALU运行,效率较高。
- HI,LO寄存器并不是通用寄存器,和其他通用寄存器的用法不一致,不能通过非乘除法指令修改和访问,因此不需要置于GRF中,内置在MDU中即可。
2、真实的流水线 CPU 是如何使用实现乘除法的?请查阅相关资料进行简单说明。
- 真实的流水线CPU采用的乘法是有加法器和移位器循环,具体实现过程为:
首先CPU会初始化三个通用寄存器用来存放被乘数,乘数,部分积。
部分积寄存器初始化为0。
判断乘数寄存器的低位是0|1,如果为0则将乘数寄存器右移一位,同时将部分积寄存器也右移一位。
在位移时遵循计算机位移规则,乘数寄存器低位溢出的一位丢弃,部分积寄存器低位溢出的一位填充到乘数寄存器的高位。
同时部分积寄存器高位补0。如果为1则将部分积寄存器加上被乘数寄存器,再进行移位操作。
当所有乘数位处理完成后部分积寄存器做高位,乘数寄存器做低位就是最终乘法结果。 - 还有另一种乘法的方式:
只需两个寄存器,A[31:0],B[63:0],A初始化为被乘数,B初始化为乘数。
每一次取B的最低位,为1则将A[31:0]+B[63:32] -> B[63:32],为0则不操作。
每次将B >> 1,然后高位补0。 - 除法实现:
与乘法的操作基本相反,首先CPU会初始化三个寄存器,用来存放被除数,除数,部分商。余数(被除数与除数比较的结果)放到被除数的有效高位上。CPU做除法时和做除法时是相反的,乘法是右移,除法是左移,乘法做的是加法,除法做的是减法。首先CPU会把被除数bit位与除数bit位对齐,然后再让对齐的被除数与除数比较(双符号位判断)。比如01-10=11(前面的1是符号位) 1-2=-1 计算机通过符号位和后一位的bit位来判断大于和小于,那么01-10=11 就说明01小于10,如果得数为01就代表大于,如果得数为00代表等于。如果得数大于或等于则将比较的结果放到被除数的有效高位上然后再商寄存器上商:1 并向后多看一位(上商就是将商的最低位左移1位腾出商寄存器最低位上新的商)如果得数小于则上商:0 并向后多看一位然后循环做以上操作当所有的被除数都处理完后,商做结果被除数里面的值就是余数。
3、请结合自己的实现分析,你是如何处理 Busy 信号带来的周期阻塞的?
- 除cnt—,和BusyReg置位以外全是组合逻辑的操作(不然可能会多出来一个空周期)
- 对于乘除指令:
- 将Busy,start_E,MDUOp_D传入HCU
- 然后md暂停信号为
(Busy | start_E) & (MDUOp_D != 0)
4、请问采用字节使能信号的方式处理写指令有什么好处?(提示:从清晰性、统一性等角度考虑)
- 对于需要写入的位置更加的直观,相当于将DMWE、DMOP写入的A[1:0]用四位字节使能信号表示,十分的统一。
5、请思考,我们在按字节读和按字节写时,实际从 DM 获得的数据和向 DM 写入的数据是否是一字节?在什么情况下我们按字节读和按字节写的效率会高于按字读和按字写呢?
- 按字节读写的时候,我们获得的是一字节,但是我们如果要lw或lh的话我们就需要拼接。如果是sw或sh的话我们需要多次存入。
- 若用lb,sb,lh,sh这种非取字的读写时,按字节读可以省去,取位,拼接的步骤,效率要优于按字读写。
6、为了对抗复杂性你采取了哪些抽象和规范手段?这些手段在译码和处理数据冲突的时候有什么样的特点与帮助?
- NPC统一,NPC统一模块,具体可见跳转分支指令实现
- 指令分类,MCU指令括号分类防止译码指令过长

- 每一级设置outMUX,只需在MCU中控制outSel即可决定转发值及写入寄存器的值
- 多用注释来对代码段进行分割,代码对齐(保持好的代码风格)
7、在本实验中你遇到了哪些不同指令类型组合产生的冲突?你又是如何解决的?相应的测试样例是什么样的?
- 实现过程见实现方法-冒险处理
- 在常规测试通过后,我们可以将T_rsUse和T_rtUse相同的指令归类为同一需求指令,把T_new相同的指令归类为同一供给指令。
- 所以可以在new方面有下列指令:add,lw,jal,mfhi
- 在rsUse方面有下面情况:add,sll,lw,beq,jr,mult,mthi
- 然后对着转发的时间表,设计测试数据:
1 | # rs0_E1 |
8、如果你是手动构造的样例,请说明构造策略,说明你的测试程序如何保证覆盖了所有需要测试的情况;如果你是完全随机生成的测试样例,请思考完全随机的测试程序有何不足之处;如果你在生成测试样例时采用了特殊的策略,比如构造连续数据冒险序列,请你描述一下你使用的策略如何结合了随机性达到强测的效果。
- 手动构造策略见上
- 完全随机生成有几大不足之处,如无法保证内存对齐,无法保证延迟槽中没有跳转分支,无法避免一定几率的死循环等等
- 但可以加入策略:
- 比如只用t0-t6寄存器以保证产生足够多的冲突
- 在检测到生成跳转后禁用跳转指令
- 检测到内存不对齐可以不生成等等

