BUAA-CO课程p5,用verilog实现五级流水线的CPU,首次操作难度较大
p5_log
设计思路-纲领
摘要
- 我们先通过对于RTL构造出无需转发的数据通路表
- 在考虑转发的情况构造出转发的数据通路
搭建电路(图文结合)
然后逐条指令分析主控制器控制信号
- 逐条指令分析$T_{use}, T_{new} $
- 构造策略矩阵
写控制表达式
这是一个自下而上的过程
- 可以先实现p5所需的基础指令
然后对于MIPS-C3架构指令集增量开发
最后构建自动化测试与样例生成器
实现指令
- 对于指令的分类很重要
- 下面是所需要是实现的指令类和指令
- 寄存器寄存器计算:add, sub, slt, sltu, and, or, xor
- 寄存器立即数计算:addi, slti, andi, ori, xori
- 位移类: sll, srl, sra, sllv, srlv, srav
- B类:beq, bne
- store:sw, sh, sb
load:lw, lh, lhu, lb, lbu
跳转并链接:jal, jalr, j
- 跳转寄存器:jr, jalr
- 加载高位:lui
- 空指令:nop
- 读乘除法寄存器:mfhi, mflo
写乘除法寄存器:mult, multu, div, divu, mthi, mtlo
p5要求实现的基础指令有:add, sub, ori, lw, sw, beq, lui, jal, jr, nop
命名规范
- 在控制信号连线名末尾加上_阶段字母,如:NPCOp_D,用以区分所属阶段
- 在寄存器输出信号前加上阶段字母_, 如:D_A1,用以区分所属阶段
- 功能部件输出信号前加上功能部件.,(实际打码时舍弃)
- MUX命名采取X_输入端口名_选择数
- 转发MUX命名采用F_输入端口名_选择数,级数越大优先级越高
模块设计
数据通路
数据通路表
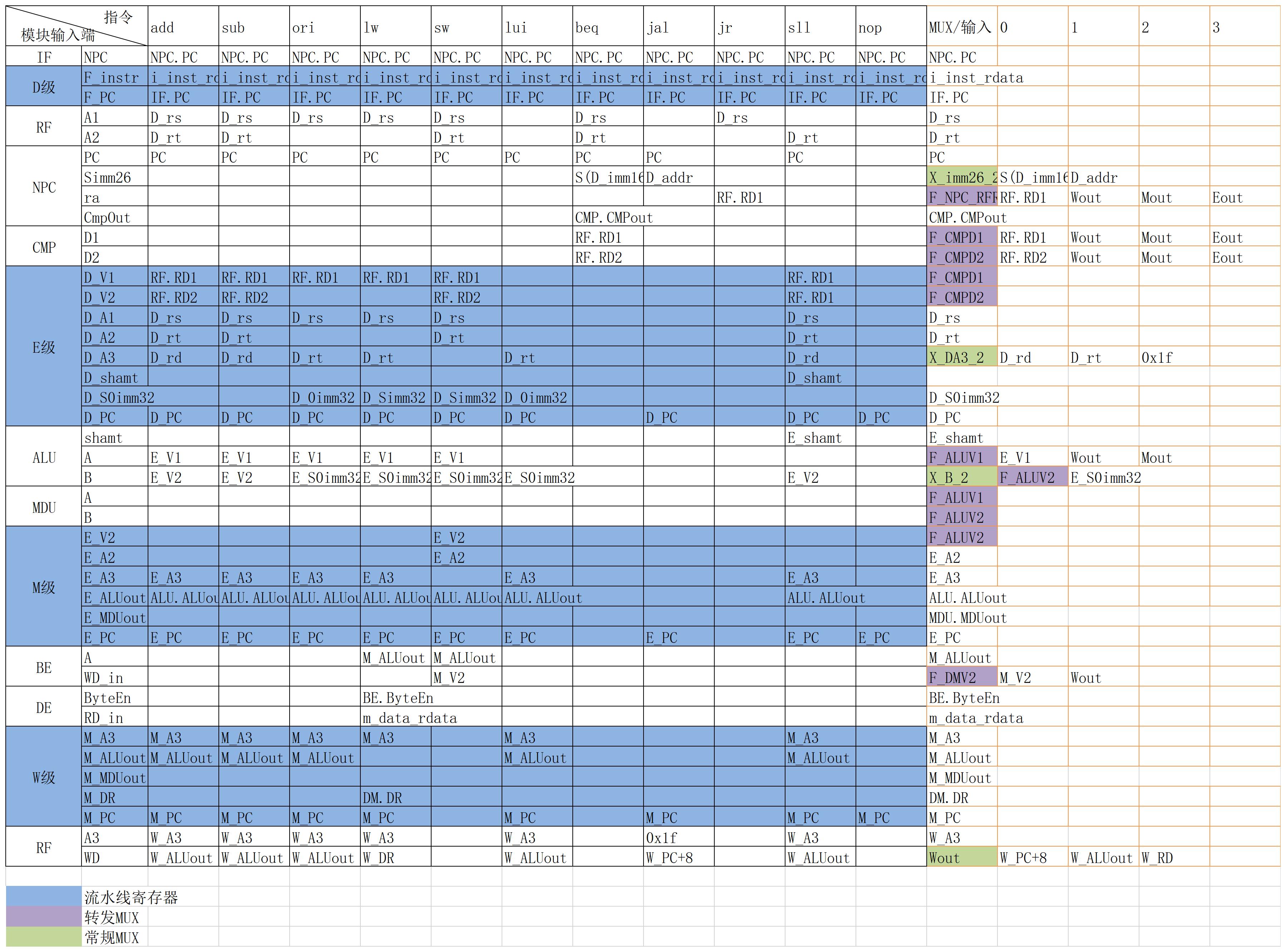
功能模块
IFU(PC\IM)
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
| en |
I |
使能 |
暂停时使用 |
| NPC[31:0] |
I |
由NPC返回,下一条指令的PC |
|
| PC[31:0] |
O |
当前执行的指令地址 |
| instr[31:0] |
O |
当前执行的指令 |
RF
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
| WE |
I |
写使能信号 |
|
| A1[4:0] |
I |
读出地址1 |
|
| A2[4:0] |
I |
读出地址2 |
| A3[4:0] |
I |
写入地址 |
| WD[31:0] |
I |
写入的数据 |
| RD1[31:0] |
O |
输出A1地址寄存器中的值 |
| RD2[31:0] |
O |
输出A2地址寄存器中的值 |
CMP
| 信号名 |
IO |
描述 |
备注 |
| D1[31:0] |
I |
待比较数据1 |
| D2[31:0] |
I |
待比较数据2 |
| CMPOp[2:0] |
I |
CMP功能选择:</br> 000: beq </br> 001: bne </br> 010: blez </br> 011: bgtz |
| out |
O |
结果为1则分支跳转,为0不跳转 |
NPC
| 信号名 |
IO |
描述 |
备注 |
| PC[31:0] |
I |
当前指令地址 |
|
| Simm26[25:0] |
I |
地址偏移 |
| ra[31:0] |
I |
返回地址 |
| CmpOut |
I |
B类指令的比较结果 |
| NPCOp[2:0] |
I |
NPC功能选择:</br> 000: 顺序+4 </br> 001: B类跳转 </br>010: jal/j </br> 011:jr/jalr |
| NPC[31:0] |
O |
下一条指令地址 |
EXT
| 信号名 |
IO |
描述 |
备注 |
| imm16[15:0] |
I |
16位立即数 |
| EXTOp |
I |
EXT功能选择:</br> 0: 0拓展 </br> 1: 符号位拓展 |
lui指令的高位拓展在ALU里执行 |
| S0imm32 |
O |
拓展后的32位立即数 |
ALU
| 信号名 |
IO |
描述 |
备注 |
| ALUOp[3:0] |
I |
ALU功能选择 |
具体对于功能后有附录 |
| A[31:0] |
I |
运算数1 |
| B[31:0] |
I |
运算数2 |
| shamt[4:0] |
I |
位移值 |
| ALUout[31:0] |
O |
计算结果 |
MDU(乘除模块)
DM
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
| WE |
I |
写使能信号 |
|
| A[31:0] |
I |
待操作数据的地址 |
| WD[31:0] |
I |
待写入的数据 |
| DMOp[2:0] |
I |
DM功能选择:000: word </br> 001: halfword </br> 010: byte </br> 1xx: 无符号拓展load |
最高位置一表示无符号位拓展 |
| DMout[31:0] |
O |
输出的32位数据 |
流水线寄存器
- 每个流水线寄存器都保存着一条指令完成后续操作所需要的的全部信息。
- 对于每一个流水线的产生结果的级次,我需要用一个MUX来确定哪个是当前指令的用于转发的有效数据,PC+8, ALUout,DMout,所以我们增加outSel的选择信号,此选择信号可以代替RFWDSel的功能
D(IF/ID)
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
| en |
I |
使能信号 |
暂停时置位0 |
| F_instr[31:0] |
I |
F级取出的指令 |
| F_PC[31:0] |
I |
F级输出的指令PC |
| D_opcode[5:0] |
O |
当前D级的opcode |
| D_rs[4:0] |
O |
rs |
| D_rt[4:0] |
O |
rt |
| D_rd[4:0] |
O |
rd |
| D_shamt[4:0] |
O |
偏移量,位移指令使用 |
| D_funct[5:0] |
O |
funtion码 |
| D_imm16[15:0] |
O |
16位立即数 |
| D_address[25:0] |
O |
26位地址 |
| D_PC[31:0] |
O |
D级当前指令地址 |
E(ID/EX)
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
暂停时置为1 |
| en |
I |
使能信号 |
| [31:0] D_V2 |
I |
| [4:0] D_A1 |
I |
| [4:0] D_A2 |
I |
| [4:0] D_A3 |
I |
| [4:0] D_shamt |
I |
| [31:0] D_S0imm32 |
I |
| [31:0] D_PC |
I |
|
| ALUOp_D[3:0] |
I |
| DMOp_D[2:0] |
I |
| RFWE_D |
I |
| DMWE_D |
I |
| BSel_D |
I |
| outSel_D[1:0] |
I |
| T_new_D[1:0] |
I |
|
| [31:0] E_V1 |
O |
| [31:0] E_V2 |
O |
| [4:0] E_A1 |
O |
| [4:0] E_A2 |
O |
| [4:0] E_A3 |
O |
| [4:0] E_shamt |
O |
| [31:0] E_S0imm32 |
O |
| [31:0] E_PC |
O |
|
| ALUOp_E[3:0] |
O |
| DMOp_E[2:0] |
O |
| RFWE_E |
O |
| DMWE_E |
O |
| BSel_E |
O |
| outSel_E[1:0] |
O |
| T_new_E[1:0] |
O |
M(EX/MEM)
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
| en |
I |
使能信号 |
| [31:0] E_V2 |
I |
| [4:0] E_A2 |
I |
| [4:0] E_A3 |
I |
| [31:0] ALUout |
I |
| [31:0] E_PC |
I |
|
| DMOp_E[2:0] |
I |
| RFWE_E |
I |
| DMWE_E |
I |
| outSel_E[1:0] |
I |
| T_new_E[1:0] |
I |
|
| [31:0] M_V2 |
O |
| [4:0] M_A2 |
O |
| [4:0] M_A3 |
O |
| [31:0] M_ALUout |
O |
| [31:0] M_PC |
O |
|
| DMOp_M[2:0] |
O |
| RFWE_M |
O |
| DMWE_M |
O |
| outSel_M[1:0] |
O |
| T_new_M[1:0] |
O |
W(MEM/WB)
| 信号名 |
IO |
描述 |
备注 |
| clk |
I |
时钟信号 |
|
| reset |
I |
同步复位 |
| en |
I |
使能信号 |
| [4:0] M_A3 |
I |
| [31:0] M_ALUout |
I |
| [31:0] M_DR |
I |
| [31:0] M_PC |
I |
|
| RFWE_M |
I |
| outSel_M[1:0] |
I |
| T_new_M[1:0] |
I |
|
| [4:0] W_A3 |
O |
| [31:0] W_ALUout |
O |
| [31:0] W_DR |
O |
| [31:0] W_PC |
O |
|
| RFWE_W |
O |
| outSel_W[1:0] |
O |
| T_new_W[1:0] |
O |
控制模块
- 此CPU采用集中译码的方式,在D级译码,控制信号进入流水,使用过的就不用进入了
- T_new产生后随着流水线递减
- 分为MCU,HCU
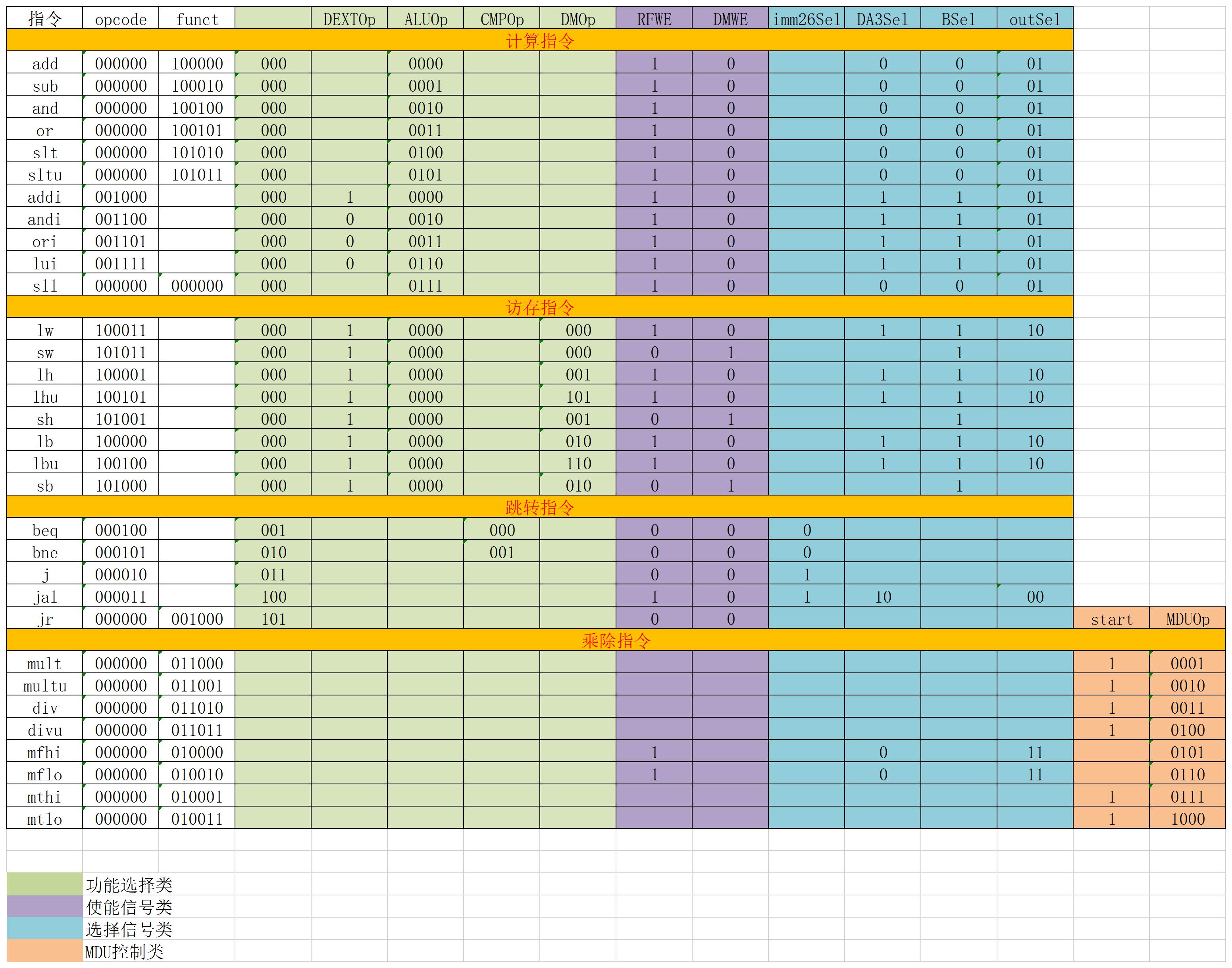
主控制器(MCU)
| 信号名 |
IO |
描述 |
备注 |
| opcode[5:0] |
I |
D_opcode |
| funct[5:0] |
I |
D_funct |
|
| NPCOp_D[2:0] |
O |
| ALUOp_D[3:0] |
O |
| DEXTOp_D |
O |
| DMOp_D[2:0] |
O |
|
| RFWE_D |
O |
| DMWE_D |
O |
|
| imm26Sel_D |
O |
| DA3Sel_D[1:0] |
O |
| BSel_D |
O |
E_ALU_B信号选择:{} |
| outSel[1:0] |
O |
有效转发数据Sel |
|
| T_rsUse[1:0] |
O |
当前指令用到rs寄存器所剩下的时间 |
| T_rtUse[1:0] |
O |
rt |
| T_new_D[1:0] |
O |
当前指令产生结果所需的时间 |
冒险控制器(HCU)
- 空行表示逻辑与功能上的分割
- 我这里只需要D级输出T_use因为我只有stall需要用到T_use,而stall应只在D级就决定,转发只需判断Tnew==0
| 信号名 |
IO |
描述 |
备注 |
| D_A1[4:0] |
I |
| D_A2[4:0] |
I |
| E_A1[4:0] |
I |
| E_A2[4:0] |
I |
| M_A2[4:0] |
I |
|
| E_A3[4:0] |
I |
| M_A3[4:0] |
I |
| W_A3[4:0] |
I |
|
| RFWE_E |
I |
| RFWE_E |
I |
| RFWE_E |
I |
|
| T_rsUse[1:0] |
I |
D级MCU输出T_use |
| T_rtUse[1:0] |
I |
D级MCU输出T_use |
|
| T_new_E[1:0] |
I |
| T_new_M[1:0] |
I |
| T_new_W[1:0] |
I |
|
| RFRD1Fwd[1:0] |
O |
NPC读入RA的转发 |
| CMPD1Fwd[1:0] |
O |
D_RD1的转发 |
| CMPD2Fwd[1:0] |
O |
D_RD2的转发 |
| ALUV1Fwd[1:0] |
O |
ALU_A的转发 |
| ALUV2Fwd[1:0] |
O |
ALU_B的转发 |
| DMV2Fwd[1:0] |
O |
DM_WD的转发 |
| stall |
O |
暂停信号 |
- Sel结尾代表常规MUX信号,Fwd结尾代表转发MUX信号
- 转发MUX的Sel的含义大致是数字越大优先级越高,优先级是E、M、W
实现方法
访存指令
跳转分支指令
- 要特别注意PC+8的转发问题,当检测到jal时转发
冒险处理
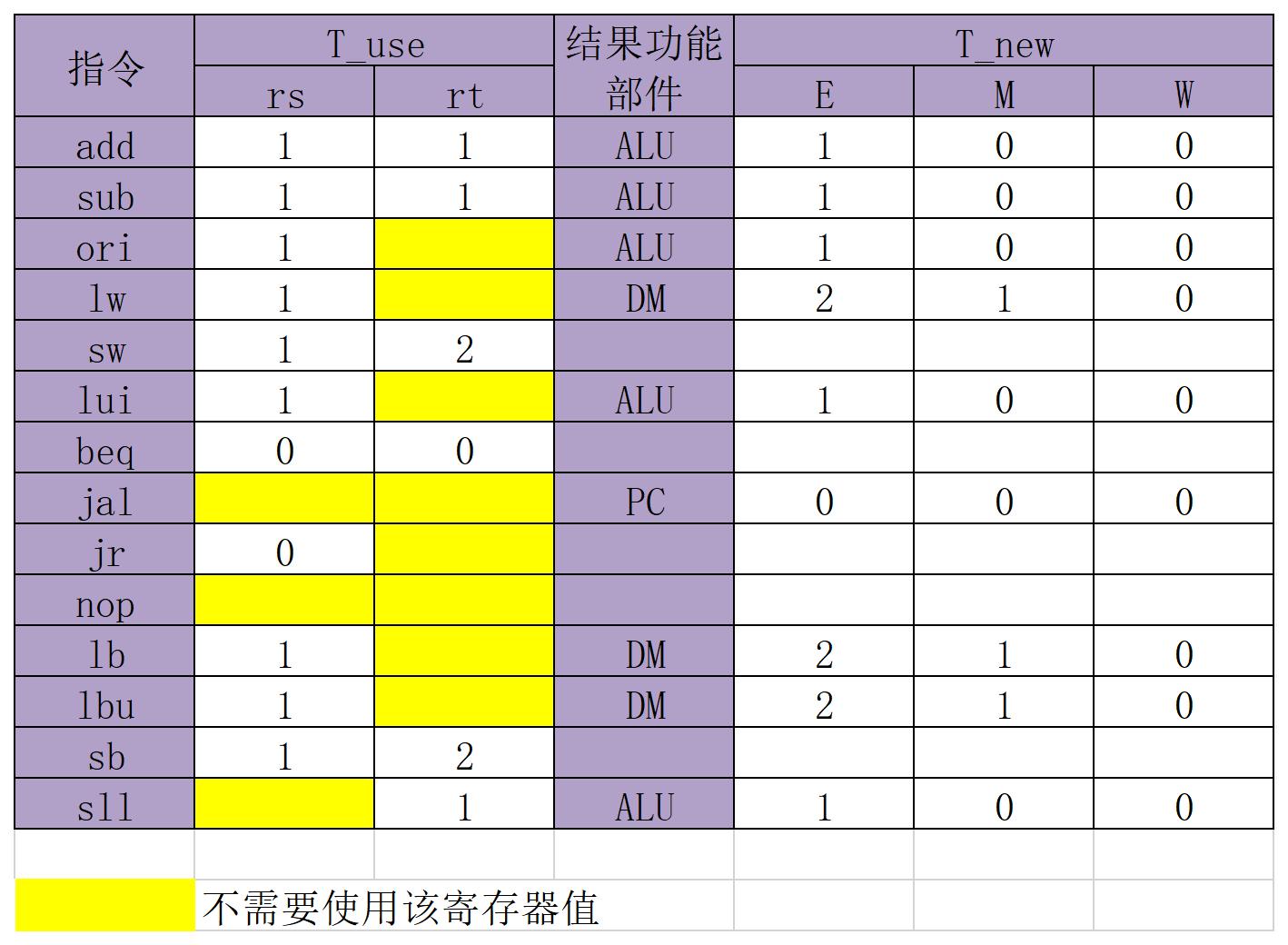
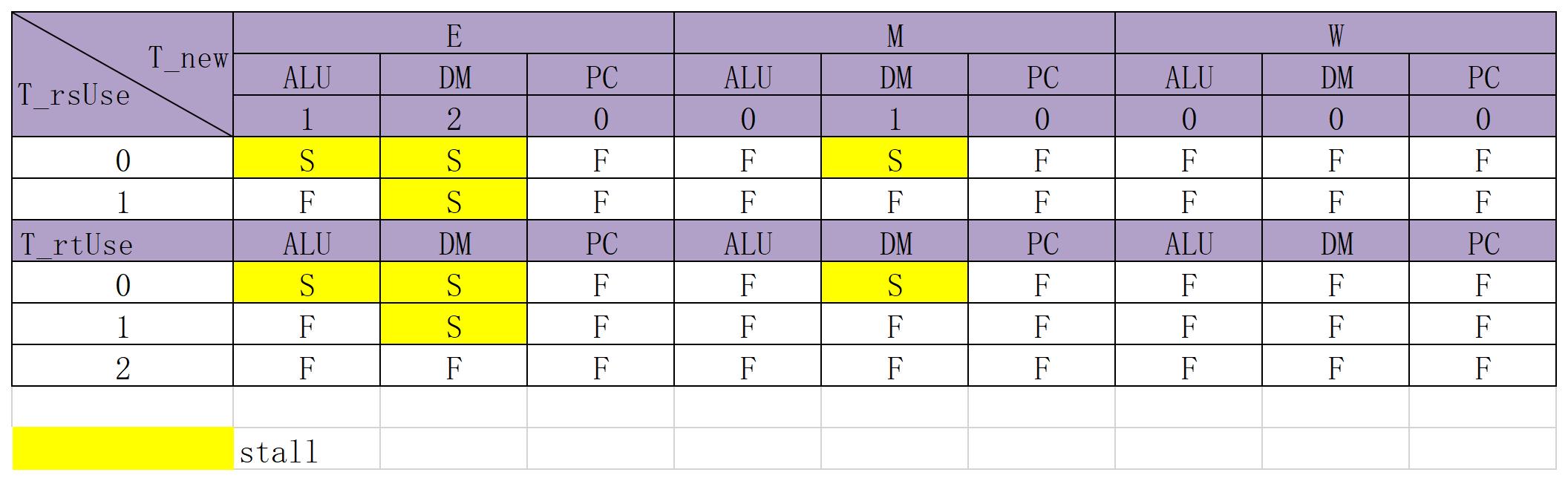
- 遵循暴力转发策略,在打好常规的数据通路表后,观察哪些端口需要用到寄存器值(需求者),再把所有的供给者的情况遍历出来
- AT法: 需求者是需要用这个值来运算的,找到所有与V,RD相关的端口;供给者是需要这个值来存入的,考虑它啥时候能够算出来。
- 因此对于 $T_{use} $ 我们只需要考虑被需求所以只可能在DEM级
- 对于
- $T_{use} = 0$: beq, jr
- $T_{use} = 1$: add, sub, ori, lw, sw
- $T_{use} = 2$: lw, sw
- 表出来后,尽量转发
- 暂停的机制:暂停IF,暂停D级,清空E级,
- 转发机制:结果出来后都转发,只需改变控制信号。
- 我们把RFWE放入HCU用以保证写使能信号有效(有效数据)
- 判断A3!=0
- 注意对于不要用的rt,rs置位2
冒险控制表
测试数据及自动化测试
常规测试
冒险测试
- 对于冲突进行覆盖性分析,需要我们根据冲突表,45种情况每一种都设计相应的冒险测试数据(建立在基础测试通过的情况下)
自动化
思考题
- 我们使用提前分支判断的方法尽早产生结果来减少因不确定而带来的开销,但实际上这种方法并非总能提高效率,请从流水线冒险的角度思考其原因并给出一个指令序列的例子。
- 我们使用两个寄存器值的时间最早来到了D级,所以很可能会引发暂停.
- 如下面这种情况,若beq的结果在E级产生,则不需要暂停,可以转发,但是现在beq在D级的时候lw还在M级,没有产生结果,需要暂停。
1
2
3
| lw $t0, 0($0)
nop
beq $t0, $t0, label
|
- 因为延迟槽的存在,对于 jal 等需要将指令地址写入寄存器的指令,要写回 PC + 8,请思考为什么这样设计?
- 因为延迟槽的存在,跳转指令的后一条必然会执行,所以需要把PC+8写入寄存器,不然jr时延迟槽内的指令会再执行一次
- 我们要求大家所有转发数据都来源于流水寄存器而不能是功能部件(如 DM 、 ALU ),请思考为什么?
- 来自寄存器的值是当前这一级的值,而功能部件输出的值是要写入下一级的,有一定的延迟,不能统一时间,转发的值就不稳定
- 我们为什么要使用 GPR 内部转发?该如何实现?
- 为了保持W级的写入和此时D级的读出是同一个值,规避数据冒险。实现方法就是在RF模块里加上一个MUX,判断当冲突条件满足时,转发。
1
2
| assign RD1 = (A3 == A1) & (A3 != 0) & (en == 1)? WD : greg[A1];
assign RD2 = (A3 == A2) & (A3 != 0) & (en == 1)? WD : greg[A2];
|
- 当然不使用内部转发的话也不是不行,可以把Wout接入RD出口的转发多路选择器。
- 我们转发时数据的需求者和供给者可能来源于哪些位置?共有哪些转发数据通路?
- 需求者有:NPC.RA, CMP.D1|D2, ALU.V1|V2, DM.WD
- 供给者:PC+8, ALU, DM
- 转发数据通路:每一级上加上一个outMUX,用于选择转发回去的结果,选择信号每条指令不同;在每个需求者端口前加上转发MUX,用于接收来自E, M, W三级的转发。
- 在课上测试时,我们需要你现场实现新的指令,对于这些新的指令,你可能需要在原有的数据通路上做哪些扩展或修改?提示:你可以对指令进行分类,思考每一类指令可能修改或扩展哪些位置。
- 增加了sll,sb|lb|lbu指令,所以课上的拓展大多数能覆盖到
- 高内聚低耦合原理:大多数只需要改变控制信号以及相应的功能模块增加功能,但不排除某些需要修改数据通路
- 对于计算类:首先改变MCU,注意每个指令的控制信号的对应,再改ALU的结构,增加输出选择
- 对于访存类:改变MCU+修改DM增加相应的功能
- 对于跳转类:修改MCU+NPC相应功能修改
- 小技巧:寻找已有的指令中与新增的指令相似的指令(可能不止一条),然后顺着这几条指令改。
- 简要描述你的译码器架构,并思考该架构的优势以及不足。
- 我当前是集中式译码
- 优势:不需要编写多个译码器
- 不足:流水线寄存器会变得十分的臃肿
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| assign NPCOp[0] = _beq | _jal ;
assign NPCOp[1] = _j | _jal;
assign NPCOp[2] = _jr;
assign DEXTOp = _lw | _sw | _lb | _lbu | _sb ;
assign ALUOp[0] = _sub | _slt | _sll;
assign ALUOp[1] = _ori | _slt ;
assign ALUOp[2] = _lui | _sll ;
assign ALUOp[3] = 0;
assign CMPOp[0] = 0;
assign CMPOp[1] = 0;
assign CMPOp[2] = 0;
assign DMOp[0] = _lbu | _lb | _sb;
assign DMOp[1] = 0;
assign DMOp[2] = _lbu;
assign RFWE = _add | _sub | _ori | _slt | _lw | _jal | _lui | _lb | _lbu | _sll;
assign DMWE = _sw | _sb;
assign imm26Sel = _j | _jal;
assign DA3Sel[0] = _ori | _lw | _lui | _lb | _lbu;
assign DA3Sel[1] = _jal;
assign BSel = _ori | _lw | _sw | _lui | _lb | _lbu | _sb;
assign outSel[0] = _add | _sub | _ori | _slt | _lui | _sll;
assign outSel[1] = _lw | _lb | _lbu;
assign T_rsUse[0] = _add | _sub | _ori | _lw | _sw | _lui | _lb | _lbu | _sb;
assign T_rsUse[1] = (_jal | _sll);
assign T_rtUse[0] = _add | _sub | _sll;
assign T_rtUse[1] = _sw | _sb | (_ori | _lw | _lui | _jal | _jr | _lb | _lbu);
assign T_new_D[0] = _lw | _lb | _lbu;
assign T_new_D[1] = _lw | _add | _sub | _ori | _lui | _lb | _lbu | _sll;
|

