
北航面向对象与程序设计课程作业,表达式展开Expr-expansion 1.0,主要设计面向对象的程序设计思想以及递归下降法文法分析的实现。
BUAA-OO 第一单元
- 包含主要知识点整理、练习题略解、作业题详解
主要知识点-从BNF看面向对象
- BNF(Backus Naur Form Notation)表示文法,用于解析字符串,详细内容涉及到编译的知识(俺暂时不是很懂
- 但是这个文法的规范化表示里,符号可以表示为类,是数据,而文法规则定义了结构的关系,由非终结符到终结符的结构蕴含着树的数据结构以及类的行为结构。
- 因此我们可以以面向对象的思想去设计结构,用递归来实现这种树状结构。
练习题略解
training-1
正则表达式:除了什么命名捕获组,逆过程之外,我们记住几点基础且重要的限定符(详细请移步菜鸟教程):
- *表示匹配前子表达式 $0 \sim + \infty $ 次
- +表示 $1 \sim + \infty $ 次
- ?表示0或1次
- {n, m}表示n~m次
IDEA有匹配正则表达式的工具,可以实时编辑调试,但好像有很多同学不知道。
- 鼠标移动到正则表达式处,右键点击后,点击第一个“显示上下文操作”
- 然后点击“检查正则表达式”,效果如图:
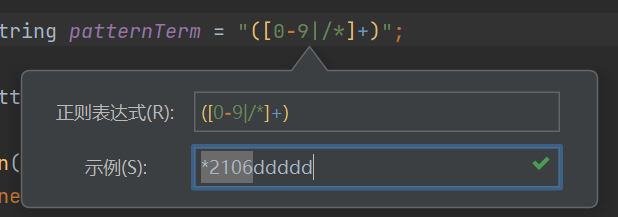
java在正则表达式中匹配*,注意转义“\*“
training-1向我们展示了用正则表达式做这题的思路,但实现起来同学会发现比较的麻烦。而且考虑到后续迭代,所以推荐递归下降法。
training-2
- 用到递归下降了
- 注意文法表述的优先级,比如,Expr->Term | Expr ‘+’ Term, 先调用Term(结束符的方向),在考虑循环加Term,更符合我们实现的结构,自己看着也会舒服点。
- 博主接下来的作业就是以training-2作为基本架构的。
作业题
形式化表述
- 表达式 → 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
- 项 → [加减 空白项] 因子 | 项 空白项 \’*’ 空白项 因子
- 因子 → 变量因子 | 常数因子 | 表达式因子
- 变量因子 → 幂函数
- 常数因子 → 带符号的整数
- 表达式因子 → ‘(‘ 表达式 ‘)’ [空白项 指数]
- 幂函数 → (‘x’ | ‘y’ | ‘z’) [空白项 指数]
- 指数 → ‘**’ 空白项 [‘+’] 允许前导零的整数 (注:指数一定不是负数)
- 带符号的整数 → [加减] 允许前导零的整数
- 允许前导零的整数 → (‘0’|’1’|’2’|…|’9’){‘0’|’1’|’2’|…|’9’}
- 空白项 → {空白字符}
- 空白字符 → (空格) | \t
- 加减 → ‘+’ | ‘-‘
看着挺复杂的,咱们化简一下叭
- 其实主体很简单:有三个最重要,表达式、项、因子
- 空白项很好处理,我们简化里就不写出了
- 下面就基本上是我们要设置的类和其中的元素的关系了,但是Num显然不需要设立一个类(这里只是为了简化表示)
- Expr -> [±] Term | Expr ‘±’ Term
- Term -> [±] Factor | Term ‘*‘ Factor
- Factor -> PowFunc | ConNum | ExprFactor
- PowFunc -> (‘x’ | ‘y’ | ‘z’) [‘**‘ [‘+’] Num]
- ConNum -> [±] Num
- ExpFa -> ‘(‘ Expr ‘)’ [‘**‘ [‘+’] Num]
- Num -> ( 0 ~ 9 ) { 0 ~ 9 }
题目需求解析&坑点汇总
保证正确性:
- 表达式因子要展开
- 展开后和项中的其他因子相乘,拆括号
- 用new BigInteger(String),不要用BigInteger.valueof(long)(会爆
- 可能会有的情况
- —-ConNum
- (-ConNum)**index
卷性能:
- 注意指数为1或0时,可以化简
- 注意系数为1、0、-1时,可以化简
- 只有整数、项、常数因子前可以有表示符号的加减,所以注意两减也可以合成为一个加,然后按照规则会出现—-、-+-、… 的情况。
- 前导零,要化简
- 三项以上的相乘可以化简为乘方,但是x**2 -> x*x
- 常数相乘算出来,注意10*10*10*10*10*10不能写成10**6,10**6不符合形式化表示,还是算出来1000000
- 表达式合并同类项
- 最简的情况应该是 $\Sigma ConNum \ast x^a \ast y^b \ast z^c $
- 把正的放在最前面,比负的放在最前面可以少一个符号(这个博主没有想到orz)
- 注意表达式和表达式因子不是同一个东西:我们可以在表达式因子中设置表达式的引用,这样实现可以保证后续迭代时多层括号的需求容易满足
- 注意我们需要统一标准,调用函数返回时,Lexer指向的是刚被操作过的位置或是还没操作过的位置,要不然会被Lexer需不需要.next()弄得晕头转向
我们提前思考一下哪些坑点需要在哪一步填
uml图
- 先简单介绍一下Unified Modeling Language,是面向对象设计的建模语言,其中最为常见的就是类图,十分的可视化。
- 类图中的不同符号表示的含义:
- 类
- 抽象类
- 接口
- 包
- 关系
- 实现关系(Realization):类实现了接口
- 泛化关系(Generalization):SubClass “is a” SuperClass.
- 关联关系(Association):A知道B的public(包含B的引用),一般为单项关联,关联又能具象化成三类
- 依赖关系(Dependency):A “use a” B.
- 是一种弱关联关系,表现为四种形式。
- B为A的局部变量
- A调用了B的static方法
- B是A的方法的参数
- B是A的方法的返回值
- 聚合关系(Aggregation):A “has a” B. eg: school has a student
- 组合关系(Composition):A “contains a” B. eg: student contains a brain
- 聚合和组合在逻辑关系上往往体现不出差别,但是可以在实际意义上区分,聚合是可以分开的,而组合关系的A与B同时存在同时消亡。这一点差别会体现代码实现上。
- 依赖关系(Dependency):A “use a” B.
“免费”的uml软件
- wps
- 亿图图示
- staruml(俺用的这个,可以通过一些小手段让他免费,见Reference,注意仅供学习
- IDEA插件
我实现的类图如下(由于课程要求,类图中并没有给出的详细方法和属性,但关系大致明了):

我的架构大致分为三个横向的组织:文法分析(Parser, Lexer),表达式结构(Expr, Term, Factor),多项式运算(Poly, Mono)
- 还记得我们上文中提到的这么多坑吗,我们需要思考在哪填这个坑是最合适的,这样你的需要的方法和属性就出现了
- 我们的大致步骤就是先用parser解析表达式,然后再在每一个元素中都加上转化成Poly类的方法。在Poly类中实现多项式相乘相加的方法。在Expr.toPloy()中,实现所包含的Term.Poly()的相加;在Term.toPoly()中实现所包含的Factor.toPloy()的相乘(也是一个递归的过程)。
- 详细实现请看下文:
递归下降分析
面向需求,我们想想要在哪一步干什么事,每一个类里需要包含哪些方法,实现哪些属性。(本文均是博主的个人实现,不代表最优方法,仅供参考,有优化的建议欢迎在评论区指出。
- Lexer需要完成的操作:
- 在Lexer就把烦人的空白字符和叠加’±’给扬咯
- 可以在初始化Lexer时就
replaceAll("[ |\\t]", "")直接去掉所有的空白字符 - 然后Lexer.next()方法里遇到’±’就把循环看看后一个字符是不是’±’,若是就合并输出
- 可以在初始化Lexer时就
- 然后我们的做法是对于不同的因子,我没必要让Parser一个一个字符的去接收然后识别,我把这个工作交给Lexer
- Lexer返回的curToken字符串中,若识别到isLetter或isDigit,就把这个因子全输出了
- 但是对于表达式因子需要特殊处理,需要交给Parser去调用parseExpr的方法
- 另外包括检测是否有指数以及将’**‘与index合并输出了,这也可以让Lexer来做
- 在Lexer就把烦人的空白字符和叠加’±’给扬咯
- 所以Lexer.next()可以这么实现(伪代码):
1 | c = input.charAt(++pos); |
注意虽然博主借鉴training-2中的做法,将因子的识别放在Lexer里面,但是识别的终究只是字符串,Lexer和Factor之间没有关系(我的类图中Lexer与Factor之间没有连线)。Parser与Lexer本身就是强聚合(组合)关系,这一点对main是隐藏的。所以放在Lexer中还是Parser中取决于自己的实现。我这里避免Paser太过于臃肿,放在Lexer中,这样Lexer每次都能直接返回一个最小化的元。Parser中需要做的仅仅是构造。
Parser类的结构也比较明了了,只需要判断Lexer返回的不同的curToken,调用不同的函数递归下降即可:
- 想想我们的表达式里的每一个元素需要什么样的属性,我们的parser需要给到一些什么属性用来构造,至于化简的事,交给后续的运算类即可。
- 但是这里有一个比较有趣的正负号的处理的问题,我们要把正负号归为谁的属性比较好呢。
- 我的实现是把正负号作为因子的属性,因为我们在Lexer中压缩了连在一起的正负号,所以一个Term的前面只会有一个正负号。但是这个正负号只能给Term的第一个因子,后续因子,若是常数,则有可能自己就带正负号。考虑这个栗子:1—x-1-2*+1。三种因子的类中都定义一个pom(plusOrMinus)的boolean值,在后续Term.toPloy()时规范输出即可。
- 所以parserExpr(),parseTerm()在解析的时候需要给后一项传入正负号的参数。
- Parser类的实现大致如下(伪代码):
1 | public class Parser { |
- 到这我们的表达式解析就可以了,我们在MainClass里也以及得到了一个包含着所有信息的Expression的对象了。
- 接下来就是运算,化简(卷性能分),字符串输出的活了。
表达式展开运算
- 本来博主为了说不弄折磨多类,简洁我的结构,把运算和化简、toString都在各个元素的类里面实现,但是后来发现不同类的属性差异巨大,我得转化成String,再运算,再转回String输出,我的类变得又臭又长(
我原本想一类多用,是不是很大胆,我一直在做一类多用简洁结构的准备,我刚开始coding的时候,我对他们说,我要一类多用,你们只需要给我20天,或者是25天,我就把程序给码完了,什么同学啊助教啊老师都很兴奋(emo歪头.jpg
- 最后我在网上搜寻一些资料,找到了往年学长的博客,看到它们的实现,感觉茅塞顿开,学长博客见Reference
- 我们设置两个类当作运算类,Poly(多项式)&Mono(单个的项,作为Poly的组成元素),我们把所有的表达式元素都转化成Poly类(单个的因子可以作为只有一个Mono的Poly,表达式因子我们可以在toPoly()中运算展开成一个大的Poly)。
- 我们上文说最后最简的结构都会是 $\Sigma ConNum \ast x^a \ast y^b \ast z^c $,所以我们的Mono的属性就一目了然了。
- 方法的设置上:
- 我们在Poly类中设置运算的方法,这个方法可以是static的并且返回一个Poly类的,也可以是只传入一个参数然后与调用方法的对象做运算但是无返回值void的。
- 设置一个addPoly()(可以做合并同类项啦),一个multiPoly()(乘方可以循环调用乘法来做),然后设置一个negPoly()(来给Poly取反)。然后每个元素的toPoly()来调用这些方法即可.
- 伪代码如下:
1 | public class Poly { |
值得一提的两个问题:
- mono的属性设置,虽说这一次作业只有三个变量xyz,但是我们要做好下一次作业就不一定了的迭代的空间。所以我们想到,一个项可以由系数,变量及其对应的指数来表示,所以系数可以作为一个单独的属性,变量和对应的指数我们可以通过HashMap< String, Integer >来管理。
- 另一个关于Poly运算方法的克隆问题,如果像我一样采取static方法来实现运算的话,我们需要保证尽量不改变传入的两个对象参数,所以我们若要采取新建一个对象,则一定需要对传入的参数进行深克隆,不然不是很安全,容易出问题。
最后,我们只需要在Poly和Mono类中实现toString()的方法,然后Poly.toString()中递归的调用Mono.toString()就行了,然后注意要卷性能分的话就得好好在这里输出了,比如特判系数或者指数为1时,隐藏,不输出。
testing 数据制造(军备竞赛)& 自动化测试
wj老师:人脑是有极限的,不可能在写代码的时候就把所有的情况都考虑到,所以测试很有必要
我:自动化测试对于无论是自己测试,还是刀人,都及其有意义(doge保命
- 一部分数据可以手搓,对于上文中整理的坑点,一个一个的对应着造出数据来,看看自己有没有问题,还可以对一些边界情况造出来,这是能够填补自动化测试的空白的。
- 比如:0,9999999e50(这个数据就刀中了人,虽然不是我刀的(泪)),—-0,。。。。
- 自动化测试的数据生成策略也可以按照文法通过递归下降来构造,概率生成不同的元素。
- python有可以检测表达式是否相等的库可以调用,命令行输入
pip install sympy- 我们检测结果的正确性只需要检查是否有括号&表达式相等即可。
- 至于性能分析,没有参照,暂时没办法做。
自动化测试由zbygg(佬!)和我一起完成,zbygg完成了data,simplify,getTest框架的搭建。(zbygg应该也会出博客,大家可以到移步友链,后续我会把它加入到Reference
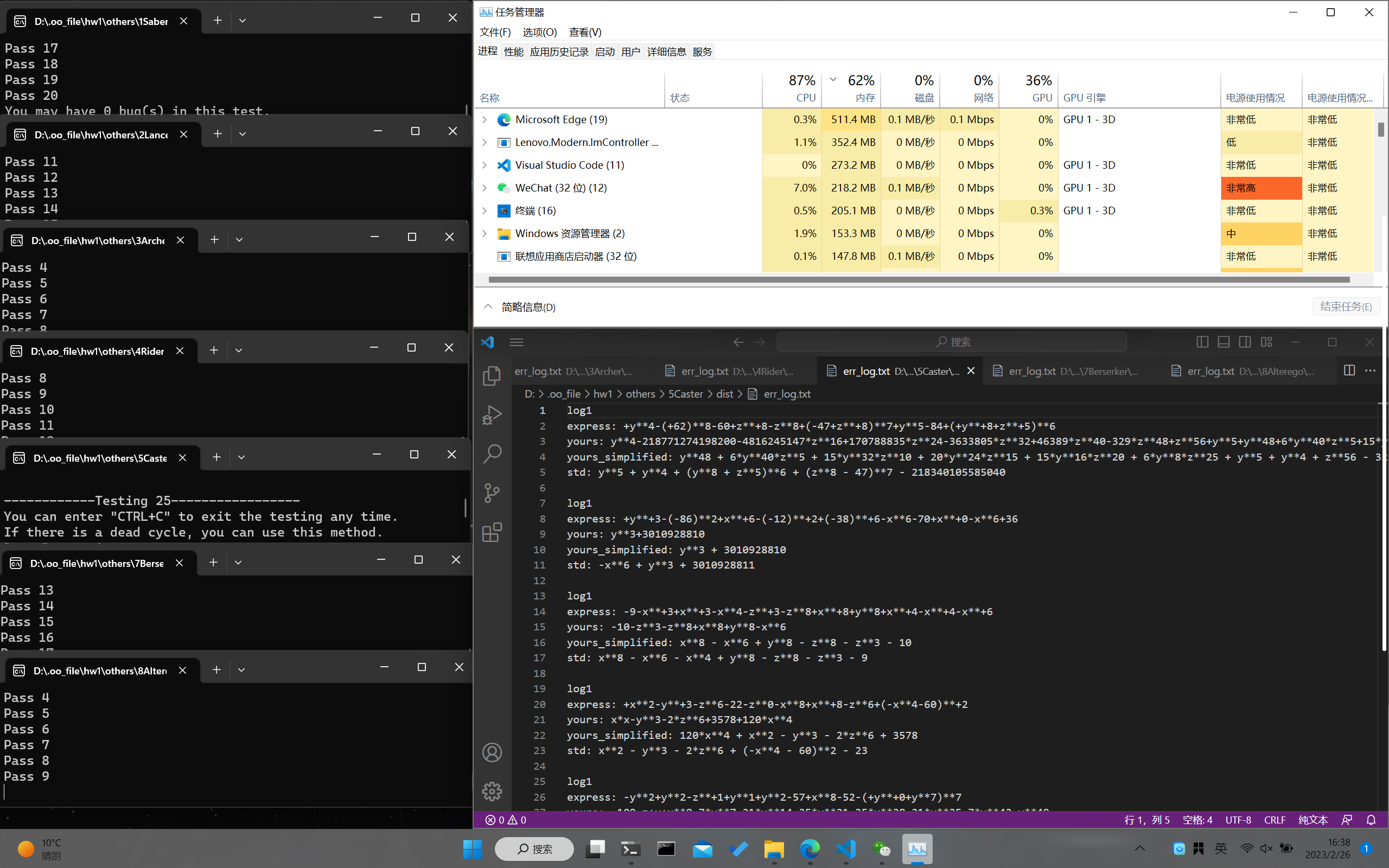
我的贡献主要是递归去除了嵌套的括号,加上了不断的循环测试,脚本化,以及后期刀人阶段的数据增强。
- 生成数据的大致架构如下(至于导出jar包测试,python表达式包的使用,循环测试,脚本化,请问度娘或者chatgpt):
1 | # 用这个全局标志来消除嵌套括号的影响 |
- 自动化造军火效果如下(有种挖矿的美
Reference
- 菜鸟教程:正则表达式
- CSDM:三步激活 StarUML V4.0.1 (WIN10) | 仅供学习
- 知乎:30分钟学会UML类图
- 学长的博客:Poly运算类的灵感来源,推荐一看
- zbygg的博客:(害没有,关注友链AugetyVolta’s Blog,有了的话第一时间放上来

